
Explore our expert-made templates & start with the right one for you.
Upsolver December 2023 Feature Summary
-
Rachel Horder
- Release Notes
- December 8, 2023
A very warm welcome to the December 2023 update. This month, I’m delighted to announce our new Datasets feature, which will enable you to observe your data for volume, freshness, and quality. Along with some other enhancements and bug fixes, we remain committed to making your data ingestion experience the best it can be, so read on to learn what we’ve been up to.
This update covers the following releases:
Contents
- UI
- Jobs
- CDC Jobs
- SQL Queries
- Enhancements
UI
New Datasets for Data Observability
Without a doubt the biggest feature we released this month – and possibly the best this year – is Datasets. While your jobs are ingesting and transforming your data, Upsolver is automatcally collecting and retaining statistics and metrics on your data. What this means for you is:
- The view of your data is immediate and shows you what’s happening in real time
- You can travel back in time to view your data at a very specific point
- There’s no need to write any code to gather the metrics – Datasets are included as standard in your account
- Datasets are included at no extra cost
- The statistics for your target data, such as the data you send to Snowflake, is visible from Upsolver, so you don’t need to run expensive queries on your data warehouse to uncover issues or perform profiling activities
Whether you’re an engineer monitoring the volume of data flowing through your pipelines, or a data consumer asking why your dashboard is showing spurious values, Datasets are available to everyone in your organization. Here are some of observability activities that datasets can help you with:
- Monitor the volume of data in your pipelines to detect peaks and troughs
- Check for data freshness and ensure dashboards are current
- Detect schema evolution to keep your data in the correct format
- Trace your data back through time to troubleshoot issues
- Check the number of expectations in your pipeline that encountered a violation
- Investigate the density of columns to check for missing data
Click on a dataset in the tree to view your statistics in real time:
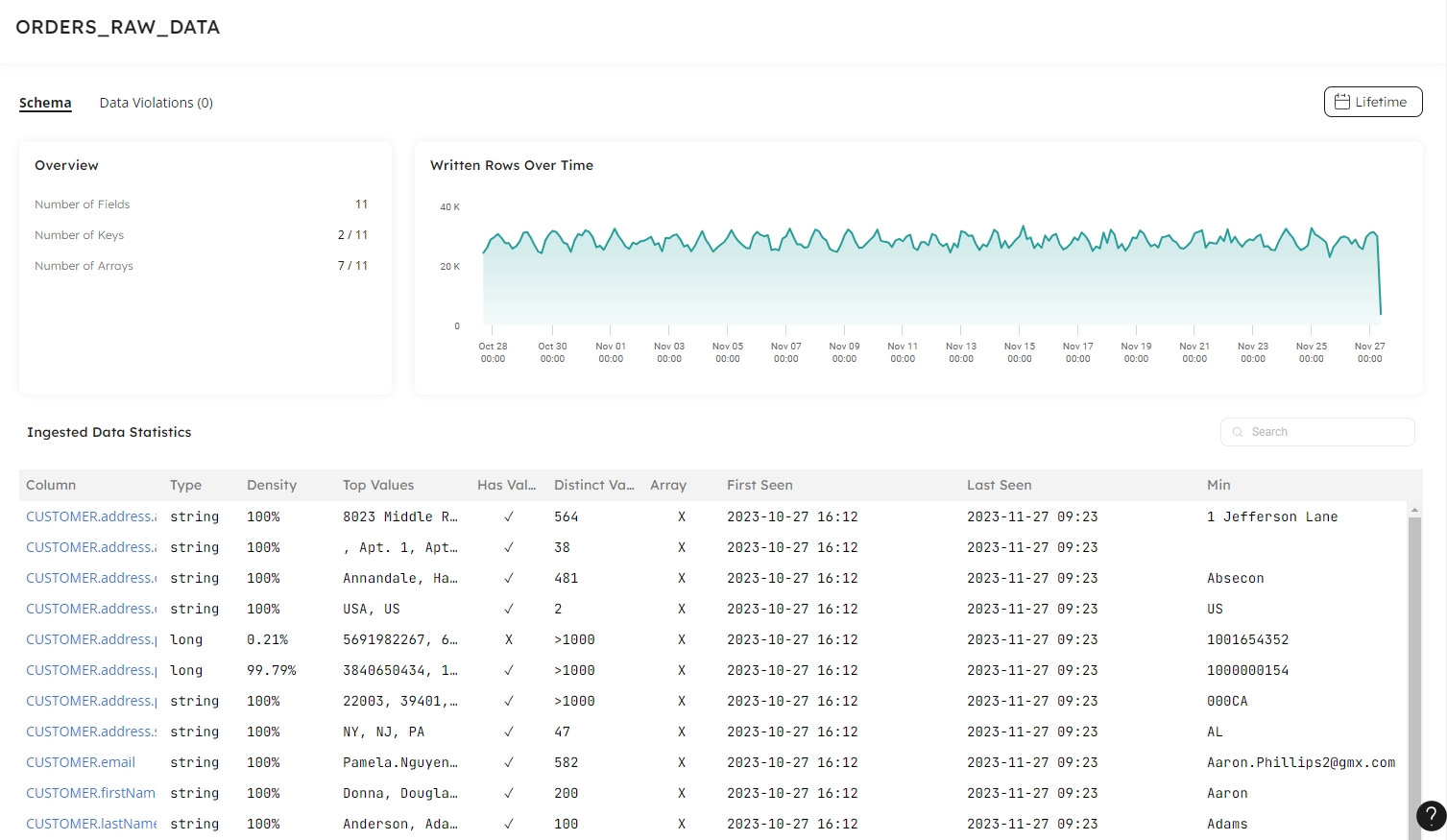
By selecting a date and time range in the Written Rows Over Time visual, you can change the view of the data and travel back in time to see the state of data at an exact point:
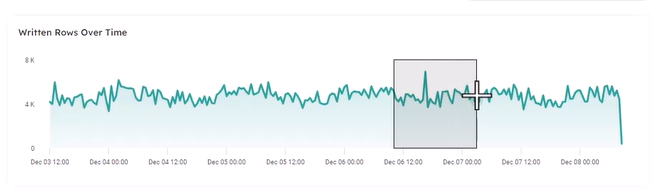
See this action:
You can also travel over an individual column, to uncover issues and see precisely what happened, for example, in the state column below:
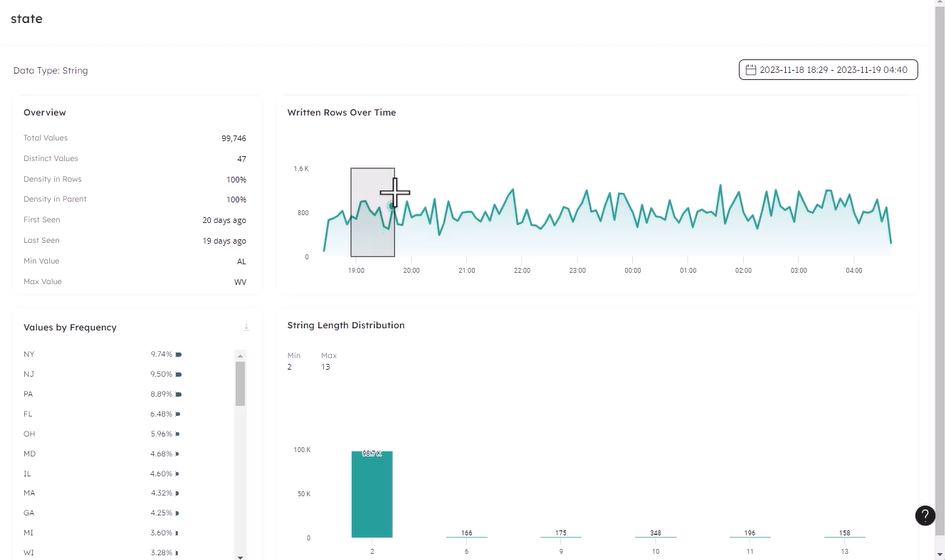
You’ll find the link to your Datasets in the main menu where you can dive straight into the statistics on your data. I can’t recommend enough that if you haven’t looked at your datasets yet, you go check them out!
This is just a small sample of the capabilities that Datasets offer. Discover more with the following resources:
- Article: The 5 Pillars of Data Observability
- How To Guide: Observe Data with Datasets
- Documentation: Datasets
New Sidebar Redesign and Improvements
Our engineering team has made improvements across the whole user-interface, to deliver a fresh and modern experience for navigating your organization. It is now easier to jump straight into your entities and, with a collapsible menu, you can expand your screen estate to give yourself extra space for coding or viewing datasets, for example.
You will find help and resources at the bottom of the menu for when you quickly need assistance from our support team, or want to reference the Upsolver documentation.
New Filter Jobs Page by Job Status
We’ve made it super easy to discover jobs by status on the Jobs page of your organization. The filters at the top right of the screen use a traffic light system to show how many jobs are in each status. The filters only show the status(es) that your jobs are currently in. This enables you to quickly discover jobs that are not running, and drill into your jobs that need attention:
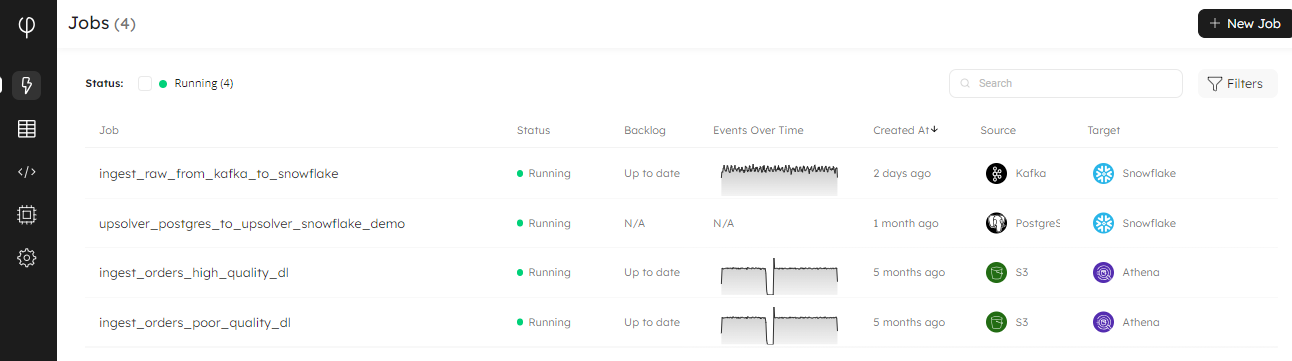
To learn more about each of the states that your job can be in, please see the Job Status documentation reference.
Fixed an High CPU for Amazon S3 Outputs While Viewing Datasets
We fixed the issue whereby some customers were experiencing high CPU for Amazon S3 outputs, when viewing their statistics in Datasets.
Jobs
Deprecated CREATE_TABLE_IF_MISSING Option for Data Lake Targets
In an effort to streamline functionality and enhance user experience, we recently announced the deprecation of the CREATE_TABLE_IF_MISSING job option specifically when copying into data lake tables. This means that the CREATE_TABLE_IF_MISSING option will not have any effect when copying into data lake tables. However, it will continue to function as expected when copying into Snowflake and PostgreSQL.
Any attempts to use CREATE_TABLE_IF_MISSING when copying into data lake tables will result in an error. We recommend reviewing and updating your existing workflows to accommodate this change. If you have any questions or need assistance, please don’t hesitate to reach out to our support team.
Fixed an Issue of a Job Reading from a System Table
An issue was identified when a job tried to read from a system table that we have now replicated and fixed, so you should no longer encounter this problem.
Fixed the Transformation Job Problem of Discarding Primary Key
We fixed a bug that was causing recent data from a partitioned table with a primary key to be discarded if the transformation job was filtering by at least one partition field.
CDC Jobs
New Append Write Option for Replication Group Jobs
Replication jobs, which use the REPLICATION GROUP feature for CDC data, now support a new write mode. If you include the APPEND write mode, you can use the new OPERATION_TYPE_COLUMN mode.
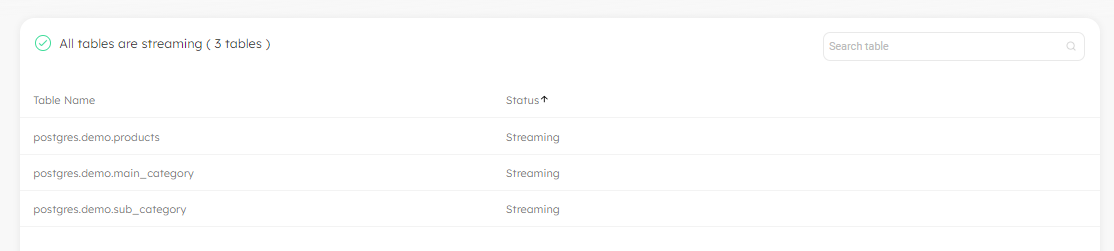
Filtered Heartbeat Table from CDC Status Display for PostgreSQL
When you create a job to ingest your CDC data from PostgreSQL and view the job status, the heartbeat table for the job is excluded from the CDC status display on the monitoring page. This enables you to focus in on your CDC tables:
SQL Queries
Fixed a Bug Causing Task Load Failure for a Future Start Time
We fixed a bug which was causing the loading of all tasks to fail if one of thoes tasks was created with a start time way in the future.
Fixed a Bug for SELECT a.* Without an Alias
Fixed a bug for SELECT a.* (without an alias) so it will behave the same way as SELECT a.* AS *, directly extracting the nested fields from object a, and returning them as separate columns instead of one object
Enhancements
Support Added for r7 Instance Types in Compute Clusters
This month we added support for r7 instance types in your compute clusters.
Fixed an Issue Preventing Ability to Create Compute Clusters
We fixed the bug whereby customers were unable to create compute clusters in their organization.
Fixed the Bug When Replay Cluster Not Shutting Down
In certain circumstances, customers were finding the replay cluster would not shut down. This is now resolved and should no longer be experienced.
That’s all for 2023! We wish all our customers a wonderful festive season and look forward to bringing you more exciting new features in the New Year. In the meantime, if you have any questions, please reach out to our friendly support team, who are on hand to help.
If you’re new to Upsolver, why not start your free 14-day trial, or schedule a no-obligation demo with one of our in-house solutions architects who will be happy to show you around.
See you in 2024!
Published in:
Blog
,
Release Notes