
Explore our expert-made templates & start with the right one for you.
Streaming Machine Learning with Upsolver and AWS SageMaker
-
 Shawn Gordon
Shawn Gordon
- Use Cases
- May 14, 2020
In a previous article, we covered one of the main challenges in machine learning: the need to set up, maintain and orchestrate two separate ETL flows – one for offline processing and creating the training dataset, and one for real-time serving and inference.
In this article, we will show the alternative – how you can use Upsolver and Amazon SageMaker to train and deploy models within the same architecture. Since we’ll be using managed infrastructure and services throughout, we’ll do this without any of the complex coding that you would need to do if you were building a solution with Apache Spark, Apache Cassandra, and similar tools.
The Use Case: Ad-click Prediction
As a quick reminder, we’re dealing with an online advertising use case where we have a stream of events coming in, representing the way users interact with ads. Each event arrives with a user ID and a campaign ID, which together tell us which ad was served to which user, as part of which campaign.
What we want to predict is if a user is going to click on the next ad. Each impression has a dollar cost and we want to optimize our ad serving so that the most relevant users are the ones seeing the ads, at the right moment. It can also go in the other direction – a user that always clicks on all of the ads so it might be some kind of bot or fraud which we want to filter. The target is to save money since each user impression costs money.
Any time that an opportunity to display an ad arrives, there are two types of information that can help make that decision:
1. Data which arrives in the event itself – for example, the user’s IP from which we can extract GEO location, User-Agent so we can infer which browser/device the user is using (if it’s a bot the User-Agent header can sometimes reveal that).
2. Historical data – for each user this reveals information about their behavior in the past, for example: how many times we saw the user, in which domains, have the user clicked in the past, general clickthrough rate (CTR). Moreover, historical data can reveal information on similar users, for example – other users from the same country – how often do they click on ads than the global average.
3.The result of an algorithmic prediction we have made about this user, or about a subset this user belongs to, which arrives in a separate stream.
By combining all of these datasets, we are giving our machine learning algorithms more data to chew on and this will hopefully lead to more accurate predictions. The more data we can provide on a user level, and the better we are at comparing our predictions to actual real-world results, the better our targeting should be in the future.
Preparing the data, training the model and running the inference
There are several steps to our machine learning pipeline:
1. Collect historical data from previous ad interactions
2. Aggregate impression and click data on the user level
3. Make a prediction based on previous user behavior
4. Test that prediction against future data to create a labeled dataset to train the model
5.Run the model in real-time in order to decide which ads to serve
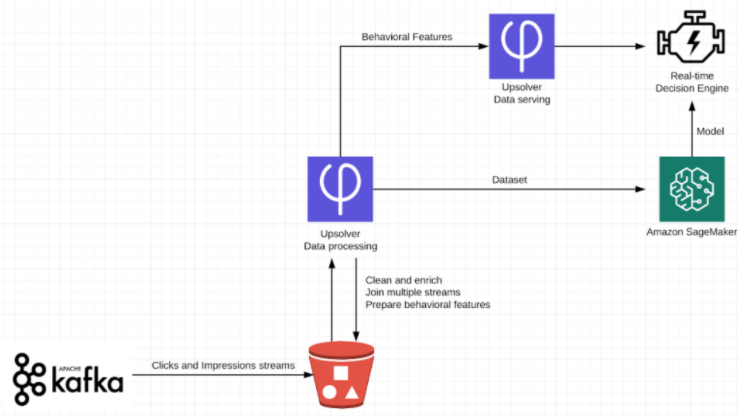
For step 1, we will assume that impression and click streams are being processed by a message broker such as Amazon Kinesis, and then written to S3.
For steps 2-4, We will use Upsolver to create user-level aggregations and to enrich each event with the outcome of the prediction (whether it turned out to be correct or incorrect) to create a labeled dataset. We create this aggregation retroactively, so that each user has both the historical data used to make the prediction as well as some instances of ‘future’ data – i.e., events against which we test that prediction. This will cover the model training.
For the real-time inference in step 5, we will again use Upsolver to create rich user profiles in real-time, which we can then feed to Amazon SageMaker in order to make the prediction and decide whether or not to serve an ad to that particular user.
Creating a labeled dataset
Getting back to our use-case, we have two streams of data:
1. Impressions – advertising opportunities that we decided to purchase
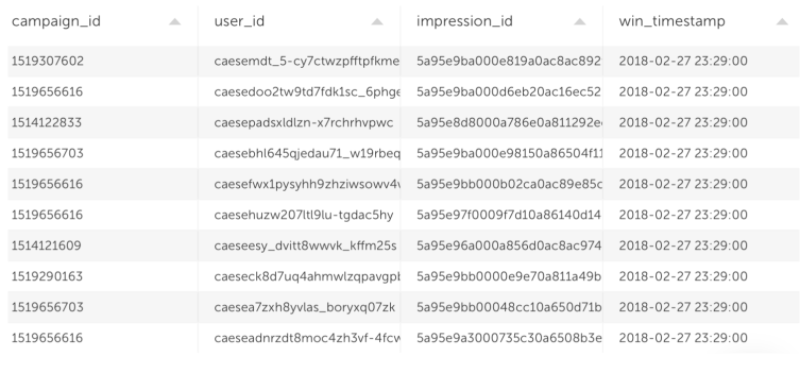
2. Clicks – users that actually clicked on an ad after we showed it to them. This is what will be used to create the labels – what we want to predict.
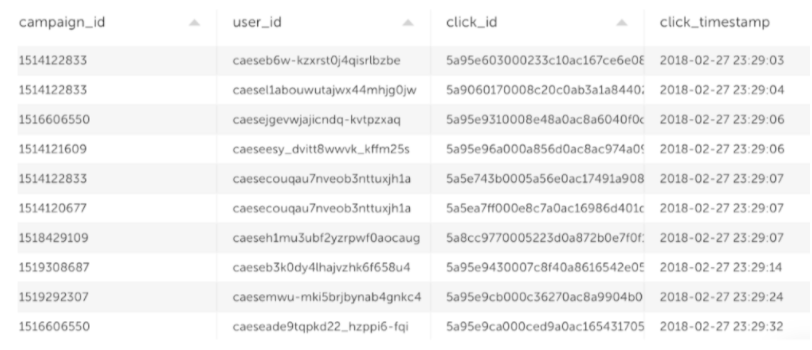
We need to join between the two streams in a way that we can train the model, but will also work in production.
What we do is that we are going to use an Upsolver Lookup Table. This is a compressed key-value store that is stored on Amazon S3. That compression gives us the ability to load any state of that Lookup Table in the past. We are not limited to the current state – similar to DBs time-travel function, but with a completely unlimited performance and time – you can look at data from a year/month/day ago with no performance concerns. The Lookup Tables can be queried using Upsolve’s API from your applications (both real-time and non-real-time).
We are going to use the Lookup Tables to do two things:
1. Get the historical data: We will define a Lookup Table where user-id will be our key and the values are the following aggregations:
-
- Number of impressions associated with this user across different campaigns
- Number of impressions associated with this user across different campaigns
2. Join the two streams to create a labeled dataset – get the data from the future which will reveal if this was a positive or negative outcome, i.e. how many times the user actually clicked on the ad.
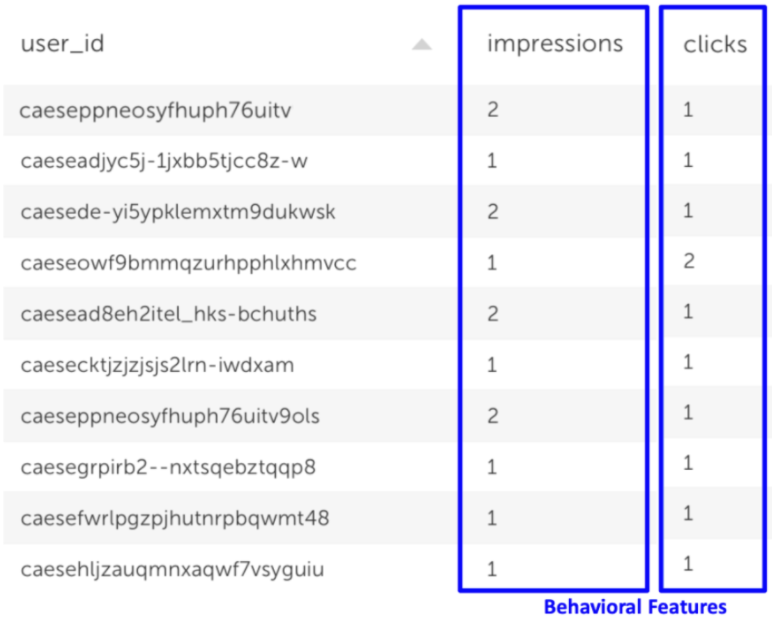
For the second part, we need to “cheat” – we need to take data from the future. To get this data we wait 15 minutes per each event that arrives before we write the data-set to SageMaker. That allows us to declaratively work with click data without needing to worry about the orchestration at all. Since all the data is coming from the same pipeline, we already know what data comes after we make our prediction (since we wait 15 minutes per each event), so we won’t accidentally use ‘future’ data in our predictions.
Sending the data to SageMaker
Upsolver supports outputting data to Amazon SageMaker, which allows you to use a Jupyter notebook-style interface to define your model on data, build your training dataset, train the model in a managed environment, and use an inference layer which you can query in order to receive a prediction response.
With this architecture we have a fully managed pipeline with minimal need for manual tuning: Upsolver continuously ETLs the data streams, while SageMaker manages the actual model state training and inference for you, which lets you query that and get the prediction response. Using both Upsolver and Amazon SageMaker means you don’t need to manage any infrastructure at all.
Upsolver and SageMaker would work closely together in both the training and online stages of our machine learning workflow:
For model training, Upsolver outputs the data to Amazon S3 as in CSV format, and there we can easily read this data with SageMaker. That CSV contains features that we are going to predict on and the label (is this a click or not). SageMaker can then run the model on the historical data and test it against the label that exists within the same data. That way SageMaker constantly has a rich dataset of very accurate data that means the machine learning model is constantly improving.
For online inference, you would use the Upsolver REST API to query a Lookup Table in real-time. Upsolver will create aggregated user profiles in real-time based on the features that the data scientist wants to look at (such as the previous number of impressions). This data is served in sub-second latency, allowing us to get more accurate results when we run the model we had previously trained.
This is an iterative process since you keep on improving your features and your model. Using Upsolver, you can do this quickly – just use the Lookups for Joins, configure the required features for your dataset and use Upsolver to send that to SageMaker. It’s all done within the same interface and using the same data – so you only have one ETL flow to run and there’s no orchestration required on the user’s side.
Want to see it in action?
Upsolver helps the world’s most innovative companies achieve faster and smarter machine learning. To see how you can use Upsolver in your data science workflows, schedule a demo today.
