
Explore our expert-made templates & start with the right one for you.
Real-time Data Warehousing Benchmarks (December 2021)
-
 Sean Spediacci
Sean Spediacci
- Streaming Data
- December 16, 2021
This article is an abridged version of our recent benchmark report comparing price and performance of several processing methods for ingesting and processing data across multiple processing methods on Snowflake. Read the key findings below, or get the full report here for free.
Why did we create a real-time data warehouse benchmark?
It’s no secret that the cloud data warehouse (CDW) market has made large advancements in recent years. Amazon Redshift was the first major leap, before Google BigQuery and Snowflake separated out compute and storage, and then Azure Synapse Analytics entered the fray. A sign of their popularity, each of these platforms now place in the Top 40 on the DB Engines ranking site.
Many companies are taking advantage of the scaling the cloud offers to port not only their structured data to the cloud but also to load complex big data as well, transforming it within the CDW to make it query-ready for data consumers. However, when we speak with customers who have adopted cloud data warehouses, we regularly hear about several challenges when using this architectural pattern:
- The cost of running these frequent, sometimes continuous ingestion and transformation processes becomes exorbitant, to the point where a separate cluster is used for preparing the data to isolate expenses. This cluster often drives the majority of the data warehouse cost.
- Data freshness is a challenge for cloud data warehouses (CDWs), which were designed as batch-centric systems, and are limited when it comes to ingesting and processing streams. This links back to costs as well, as some CDW vendors price based on the time the warehouse is running, regardless of the load, so that even a continuous trickle of data incurs the full charge. As organizational requirements move from nightly or weekly batches to hourly, per-minute or event-based freshness, this challenge will be an important one to overcome.
- Creating and maintaining production-grade pipelines takes both valuable data engineering time and additional orchestrations software, such as Apache Airflow or dbt, that add costs and require specialized engineering effort to build and maintain. While these orchestration solutions are useful – they are often used because it is what is familiar rather than what is best (i.e. when all you have is a hammer, everything looks like a nail).
To understand these challenges, we decided to run a simple benchmark comparing the cost and speed of four approaches to processing a stream of data into three analytics-ready tables. We ultimately compare the performance and costs differences of using Upsolver to serve a CDW versus preparing the data within the CDW itself using 3 popular strategies.
Our goal is to help customers understand what is required when it comes to developing an architecture that could handle continuous data processing. Additionally, these choices needed to be economical while keeping the scale of future business growth in mind.
What’s in it for us?
Upsolver is a cloud-native data transformation engine that runs declarative SQL pipelines on a cloud data lake. Upsolver reduces data engineering overhead for pipelines by turning SQL-defined transformations into end-to-end pipelines instead of requiring the creation and orchestration of siloed smaller jobs. It also leverages affordable cloud object storage and Spot instances to reduce the cost of running pipelines.
Many of our customers use Upsolver to feed live, pre-aggregated data to their downstream systems (e.g data lake, CDW, Kafka topic, etc). Since Upsolver runs incremental processing and leverages indexes for stateful computations, it has been found to greatly reduce compute cost when compared to batch systems.
What did we test?
This benchmark compares several approaches to implementing near real-time analytics using the Snowflake Data Platform. We tested four popular methods to quantify the differences and trade-offs across sometimes competing requirements such as:
- End-to-end latency: from raw data ingestion to analytics-ready data
- Costs: from both cloud infrastructure and human resources
- Agility: time to create each pipeline and configure the supporting systems
- Complexity of infrastructure: What will the data team need to maintain
In the test we measured the development time, run time and compute cost it took to incrementally update a large data set into three aggregated tables, on a per minute and per hour basis.
The four methods we compared were:
- Upsolver to Snowflake: Data is ingested and processed by Upsolver before being loaded into Snowflake query-ready target tables.
- Snowflake Merge Command: The new data is matched and then merged into the existing table targets.
- Snowflake Temporary Tables: The new data is aggregated into a new temporary table before replacing the current production table, after a merge, and after deleting the old tables.
- Snowflake Materialized Views: Snowflake native functionality that allows customers to build pre-computed data sets that can improve query performance, but do come with a trade-off of additional processing time and cost.
The Results: What you came here for
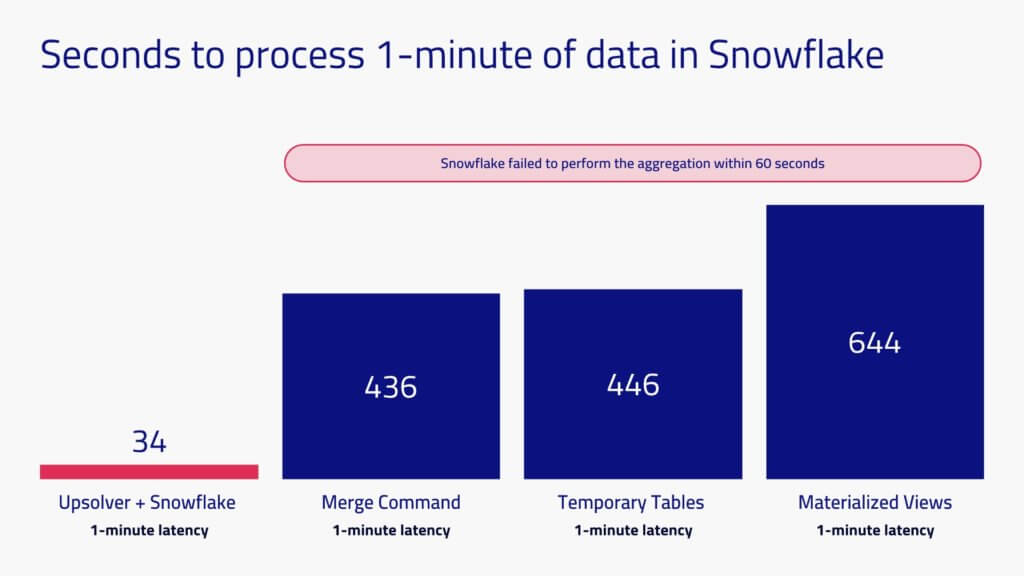
Per-minute Aggregations Weren’t Possible in Snowflake Data Warehouse
When we tried to keep Snowflake up to date on a per-minute basis, we could only do so by preparing the data using Upsolver. The three methods where preparation occurred within Snowflake took 7 to 11 minutes to process one minute’s worth of data.
What about 1-hour Latency?
Since per minute loads were not achievable within the CDW, we decided to test hourly incremental data loads.
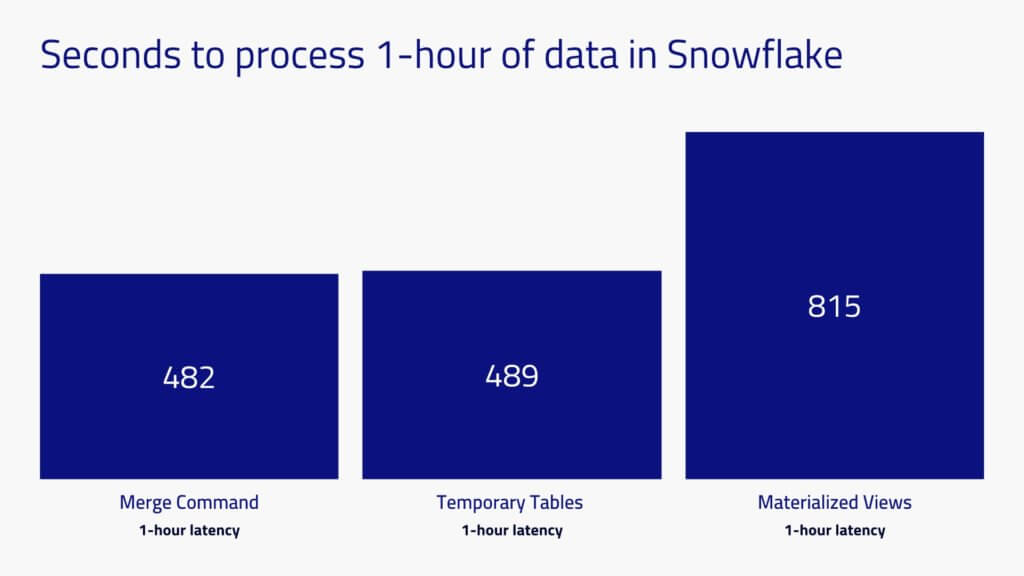
Snowflake was able to handle the same data batched in 1-hour increments, taking only marginally more processing time than for one minute batches. The reason is that Snowflake had to perform a full table scan of the historical data set in order to know where to update and where to insert, and this takes the same amount of time regardless of the size of the incremental data coming in.
The results above were obtained after applying additional optimizations such as clustering and ordering on the tables, which while possible for a benchmark, may not be practical to maintain in a real world production environment.
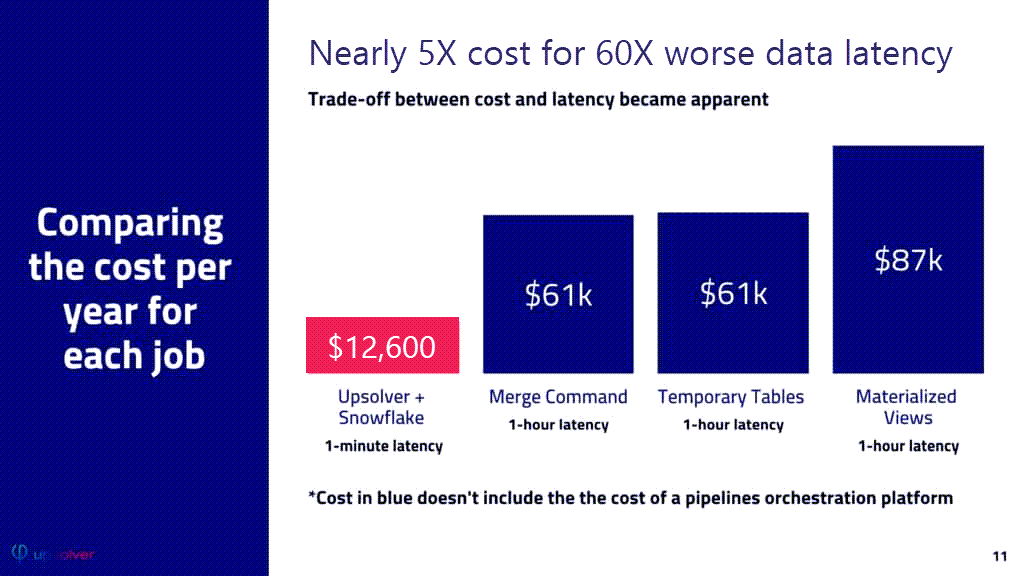
Comparing Costs Across the Four Methods
We compared the cost of processing hourly batches for the three Snowflake-only methods with the cost of processing 1-minute batches using Upsolver to load Snowflake. Ingesting and processing 1-hour of data in Snowflake was 66% to 78% more expensive than using Upsolver with 1-minute batches.
Compute cost is only one part of total cost of ownership. We measured the time it took to develop the pipeline and there was a substantial difference – 2 hours for Upsolver and 15 hours for Snowflake. One would expect that maintenance of the pipeline to reflect change requests and fixing issues would have a similar difference in work-time. Also, an orchestration service is required to optimize the processing job in Snowflake, which may have it’s own cost (if you choose a commercial service) and certainly adds personnel costs for running and maintaining the pipeline. Since Upsolver automates end-to-end pipeline orchestration with declarative SQL, this added expense and work is avoided.
Lambda Architectures are Problematic
There was another option we evaluated and discounted due to complexity, which the benchmark does not cover. It is possible to get real-time results with a lambda-based architecture. This can be seen in the below diagram.
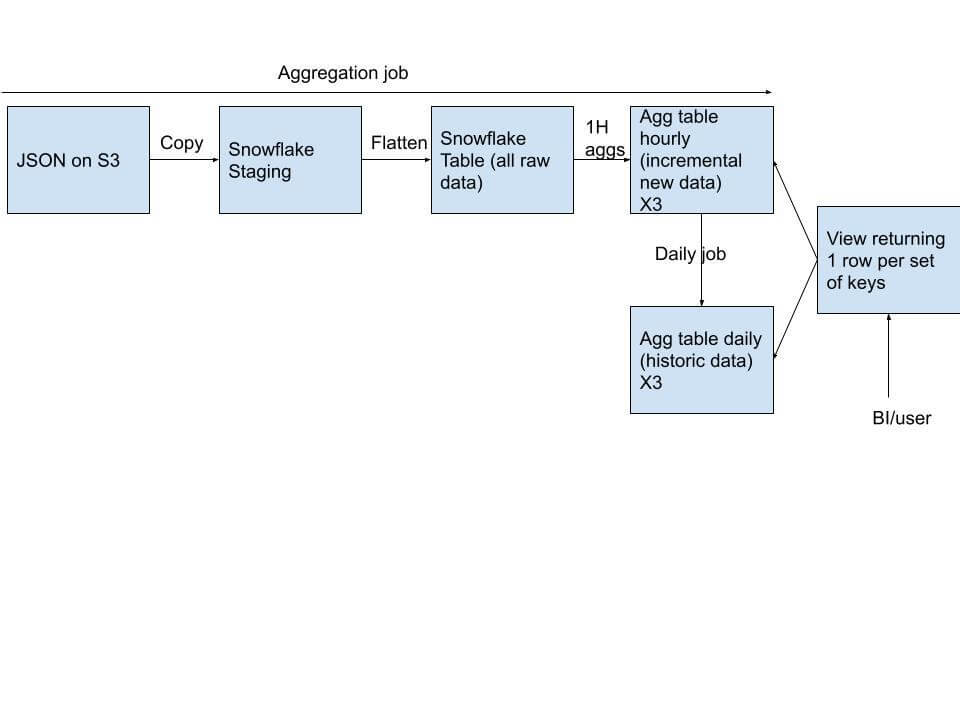
The trade-off here is that your organization will incur even more complexity.
- Duplicated logic: You will need to duplicate transformations with similar logic for different tables. If the logic needs to be updated, you will need to maintain and change in two places.
- Brittle dependencies: Your pipeline is more error-prone since you have multiple flows of the same logic and any underlying changes can potentially break the flow.
- More engineering: As with any complex DAG, the data engineering resources required to keep the DAG in sync and reliable as the complexity will ultimately grow (e.g. with evolving business requirements by the data consumers)
- Only good for append-only use cases: this model doesn’t support late arriving data and will not perform non-additive aggregates such as “COUNT DISTINCT”
Given this, we cannot recommend the Lambda architecture to users. You will have to refactor the business logic and spend more development time to replace it due to the numerous trade-offs, such as append-only modeling, which will cause friction with business users.
Batch systems are not designed for continuous processing
This benchmark indicates that even leading CDW platforms like Snowflake have challenges running continuous workloads without adding significant cost and architectural complexity. While cloud data warehouses serve users well when they need to handle data in batches, there are times when a business needs to continuously ingest and process data to provide data freshness closer to real-time (such as log analysis, usage-based alerting, operational dashboards for customer service, embedded analytics experiences, and so on).
By using Upsolver to serve prepared data into Snowflake, we improved latency while reducing processing costs and development time. Specifically we were able to:
- Reduce continuous processing costs by at least 66%
- Reduce pipeline development time by ~90% (2 hours with Upsolver vs 15 hours of coding, scripting and optimization in Snowflake)
- Improve latency of analytics-ready data from 1-hour to 1-minute
Upsolver’s ability to efficiently provide incremental processing makes it possible to continually load fresh data into Snowflake, at a fraction of the cost of refreshing aggregates on an hourly basis. In short, Upsolver eliminates the trade-off between data freshness and affordability while also reducing operational complexity.
Declarative pipeline development also makes life easier for data engineers. They can deliver reliable pipelines using SQL and without building complicated DAGs with orchestration tools like Airflow or dbt. In the same way the optimizer inside a database automatically generates an execution plan for a query, Upsolver automatically generates an end-to-end plan, while handling all the complexity, for pipeline processing.
Ultimately, CDWs are optimized for serving user queries from batch data, not for continuous data processing. As organizations move to a best-of-breed approach to outfit their modern data stack, it’s imperative that they evaluate which systems should serve which workloads as they architect for the future.
Read the rest of the benchmark report to see the full results and appendices including SQL snippets. Get it here.
Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Streaming Data