
Explore our expert-made templates & start with the right one for you.
Iceberg 101: Ten Tips to Optimize Performance
-
 Upsolver Team
Upsolver Team
- Data Lakes
- June 20, 2024
TLDR:
To optimize query performance and manage costs, we recommend:
- Partitioning data
- Sorting data
- Compacting small files
- Expiring old snapshots
- Removing orphaned field
- Automating optimization tasks
- Choosing the appropriate write isolation level
- Managing snapshot retention
- Monitoring performance
- Testing 3rd party integrations
Simply adopting the Apache Iceberg table format is not enough to guarantee optimal performance and cost savings. Unoptimized Iceberg tables can lead to slower query times, higher storage costs, and reduced overall system performance. Below we explain the why and how of Iceberg performance optimizations.
Why Optimize Iceberg Performance?
Query performance: Most large-scale data initiatives are concerned with maintaining fast query speeds as data volume increases. When Iceberg tables are not optimized, queries may need to scan through large amounts of unnecessary metadata and data, leading to slower performance. This is particularly problematic in scenarios where data is being ingested from streaming sources, like CDC, as this can quickly lead to frequent table commits and the creation of many snapshots and small files that can significantly impact query efficiency.
Storage costs: Unoptimized tables often contain redundant or obsolete data, as well as orphaned files that are no longer referenced by the table metadata. This can lead to a significant increase in storage usage and associated costs, particularly in cloud environments where storage is billed based on consumption.
By taking steps to optimize Iceberg tables, organizations can ensure that their data lakehouse remains performant and cost-effective even as data volumes grow – and is essential for organizations looking to get the most value out of their data lakehouse investment.
10 Tips to Optimize Iceberg Performance
The following tips are covered in much greater detail in our webinar on Iceberg optimization techniques. You can watch the full video for free right here.
1. Partition your data
Partitioning data based on query patterns can significantly improve query performance by reducing the amount of data scanned. Iceberg’s hidden partitioning feature allows for easy partition evolution without the need to rewrite data. This means you can define partitions as a table configuration and Iceberg will handle the mapping of source data to partition values, making it easier to adapt to changing query patterns over time.
A Spark example:
CREATE TABLE prod.db.sample (
id bigint,
data string,
category string,
ts timestamp)
USING iceberg
PARTITIONED BY (bucket(16, id), days(ts), category);
2. Sort your data
Sorting data based on commonly filtered columns can optimize data skipping during queries. By storing min/max values for each column in the metadata, Iceberg can quickly determine which data files need to be scanned for a given query. For tables with multiple high-cardinality columns, consider using Z-ordering to improve query performance by optimizing the layout of data for multi-dimensional filtering.
Example of ordering a table at creation time:
CREATE TABLE prod.db.target USING iceberg AS SELECT … FROM prod.db.source ORDER BY 1, 2;
Example of a z-order sort during compaction:
CALL catalog_name.system.rewrite_data_files( table => 'db.sample', strategy => 'sort', sort_order => 'zorder(col_1, col_2)' );
3. Compact small files
Streaming data ingestion can create numerous small files that slow down queries. Regularly compacting these files into larger ones can significantly improve query performance and reduce metadata overhead. Iceberg provides built-in support for file compaction, but automating this process using tools like Upsolver can help ensure that tables remain optimized without manual intervention.
CALL catalog_name.system.rewrite_data_files('db.sample');
4. Expire old snapshots:
Every change to an Iceberg table creates a new snapshot. This enables write isolation and allows time travel queries. However it can lead to metadata growth over time. Expiring old snapshots that are no longer needed can help manage this growth and reduce storage costs. You can define a snapshot expiration policy to automatically remove snapshots older than a specified age or beyond a certain number of snapshots, helping to keep metadata growth under control.
ALTER TABLE prod.db.sample SET TBLPROPERTIES (
'history.expire.max-snapshot-age-ms'='432000000',
'history.expire.min-snapshots-to-keep'='1'
);
CALL catalog_name.system.expire_snapshots('db.sample');
5. Remove orphaned files
Orphaned metadata and data files that are no longer referenced by the table should be periodically removed to free up storage space and improve query performance. Iceberg provides functionality to identify and delete these orphaned files, which can help keep the table clean and optimized over time. Automating this process using tools or scripts can help ensure that tables remain clean without manual intervention.
CALL catalog_name.system.remove_orphan_files(table => 'db.sample');
6. Automate optimization tasks
Implementing tools like Upsolver can help automate tasks such as compaction, snapshot expiration, and orphaned file removal, ensuring that tables remain optimized without manual intervention. This can save significant time and effort for data teams, while also reducing the risk of performance degradation due to neglected maintenance.
7. Choose the appropriate write isolation level
Iceberg offers two write isolation levels: serializable and snapshot. Serializable isolation provides stronger consistency guarantees but may impact write performance, while snapshot isolation allows for higher write concurrency but may result in non-serializable anomalies. Choose the appropriate level based on your consistency and concurrency requirements to optimize write performance.
ALTER TABLE prod.db.sample SET TBLPROPERTIES (
'write.delete.isolation-level'=serializable,
'write.update.isolation-level'='serializable',
'write.merge.isolation-level'='serializable'
);
8. Manage snapshot retention
While retaining more snapshots enables time travel queries further back in time, it also increases storage costs. Find the right balance between snapshot retention and cost based on your organization’s needs. Consider using a tiered storage approach, where older snapshots are moved to cheaper storage tiers to reduce costs while still enabling time travel.
In Upsolver, table retention can be configured as follows:
CREATE ICEBERG TABLE prod.db.sample()
PARTITIONED BY $event_date
TABLE_DATA_RETENTION = 5 days
9. Monitor performance on an ongoing basis
Optimizing Iceberg performance is not a one-time task, but an ongoing process. Regularly monitor your Iceberg tables to identify performance bottlenecks, and be prepared to adjust your optimization strategies as your data and query patterns evolve over time.
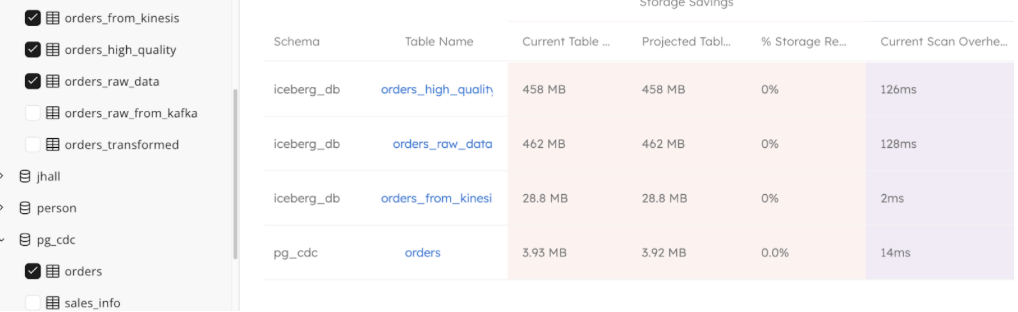
Use Upsolver to view your table health, performance and distribution in one place:
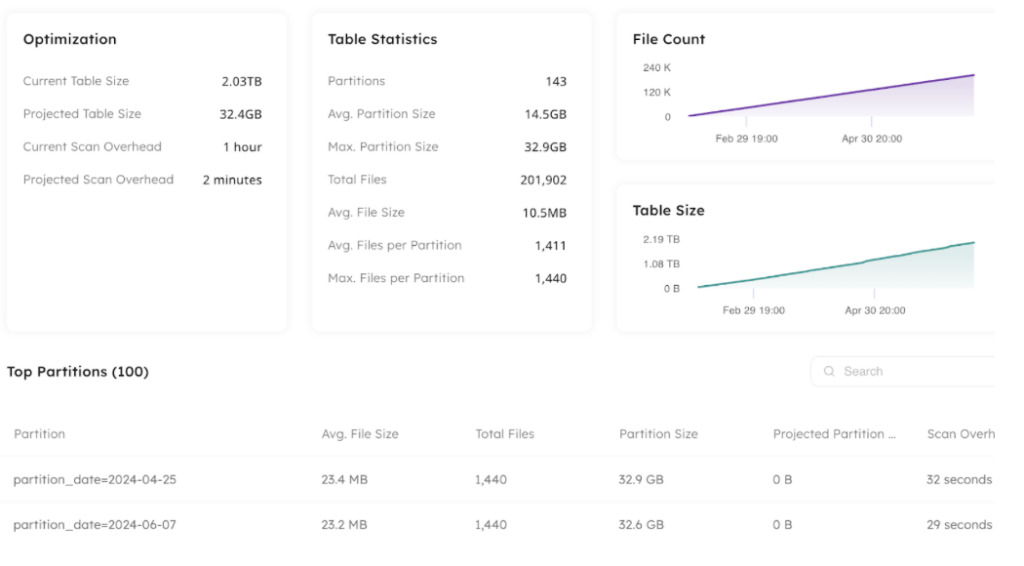
10. Test 3rd-party integrations before going live
While Iceberg is designed to be an open and interoperable table format, the level of support and performance may vary across different query engines and tools. Thoroughly test your Iceberg integrations to ensure they meet your performance and functionality expectations, and be prepared to work with vendors to address any issues.
By following these best practices and considerations, in addition to the specific optimization techniques covered earlier, you can ensure that your Apache Iceberg deployment remains performant, cost-effective, and aligned with your business requirements over the long term.
Learn More About Iceberg Performance Optimization:
- Watch the recorded webinar: Advanced Techniques for Optimizing Iceberg Lakehouse Performance, or read the accompanying article on LinkedIn
- See how your Iceberg tables stack up: sign up (for free), add your catalog and let us show you.
Published in:
Blog
,
Data Lakes