
Explore our expert-made templates & start with the right one for you.
How to Modify Continuous Data Pipelines with Minimal Downtime
-
 Jason Hall
Jason Hall
- Building Data Pipelines
- November 1, 2022
How you can update transformation logic in production
With batch-oriented pipelines, making planned changes is relatively simple. In between scheduled batch jobs you have time to update transformation logic; as long as you can make your change before the next operation starts, the pipeline output is updated on schedule.
Unplanned changes, however, are another story. If a pipeline was disrupted because of bad data, either on input or output, making the necessary changes becomes far more complex. Developers, assisted by operations staff, must stop orchestrated processes in order, while also ensuring they understand any potential impact of the disruption. If the pipeline was impacted by bad data, engineers must perform diagnostics to understand what data was affected and how it can be corrected.
But with streaming pipelines there is no “in between;” pipelines run in continuous fashion. If you don’t have a window during which to make a change, how can you modify a pipeline without disrupting the pipeline output? This blog discusses a straightforward workflow you can put in place to ensure that production pipelines can be modified – with minimal downtime and maintaining the integrity of pipeline output.
Considerations When Modifying a Data Pipeline in Production
Before deciding on the exact process for modifying your pipeline, you must first consider why you’re making the change in the first place:
- Are you trying to add some additional functionality to your existing transformation?
- Are you addressing some kind of schema evolution in the source data?
- Are you eliminating some bad data that’s begun appearing in your source?
- Is the output currently causing any disruption to a downstream process or report?
The answers to these questions impact how you proceed. For example, if your current pipeline is causing a downstream problem, you may want to stop it immediately. Otherwise you may wish to leave it running while you develop and eventually implement your changes.
Then there’s the issue of actually making the change. Traditionally, data engineers have had only partial or complex solutions to enable changes to data pipelines that are perpetually on. First, you must consider which batch jobs dependent on the continuous pipeline in question must be stopped and what impact those outages may have on downstream processes. Also, batch processes may have to be stopped in the proper order, otherwise you risk generating invalid or corrupt data. Second, what do you do with data that has already been transformed? Overwrite it? Delete it? How to handle not just the pipeline itself, but also the data the pipeline has been producing, can be a significant undertaking.
In general, to modify pipelines without disruption you must architect a solution in which raw source data is copied into a cost-effective immutable store that allows for reprocessing (also known as “time travel” and “replay”) when you’ve made your change. Upsolver SQLake is one solution that offers this as a native capability.
Below we describe how to pause a data source while it is being fixed, as well as how to change transformation logic – in both cases replaying the data so the output retains full data integrity post-change.
How Upsolver SQLake Enables On-the-Fly Revisions to Continuous Data Pipelines
Upsolver SQLake provides a different approach for building stateful, self-orchestrating pipelines using only SQL. Its ability to blend streaming and batch data gives you a new, simpler way to make changes to production pipelines.
Here’s a brief demonstration using 4 straightforward steps to make modifications to production pipelines in SQLake:
- Halt the currently running processes.
- Modify your pipeline job.
- Create your modified job.
- Delete your previous job.
Step 1: Halt the Currently Running Processes
In Upsolver SQLake, pipeline components are referred to as jobs. You use jobs to ingest data from source systems, such as Amazon S3 buckets, Amazon Kinesis streams, or Apache Kafka topics. You also use jobs to perform transformations on ingested data, pushing that data out to a target system (either a data lake or data warehouse). If you must halt your pipeline process immediately, whether data ingestion or transformation, you can run an ALTER JOB command that sets the END_AT property to NOW. This tells the job to stop processing immediately.
Below is an example of this, stopping a transformation job that was created and deployed via the S3-to-Amazon Athena template in SQLake:
ALTER JOB transform_orders_and_insert_into_athena_v1 SET END_AT = NOW;
If you don’t need to halt your pipeline immediately, you can also pass a future TIMESTAMP into the END_AT configuration of the existing job. To minimize any disruption you might choose a timestamp during a maintenance window over the weekend:
ALTER JOB transform_orders_and_insert_into_athena_v1 SET END_AT = TIMESTAMP '2022-09-18 00:00:00';
When this configured timestamp has passed, the existing job stops processing. If the job is a data ingestion job, no new data is ingested into your staging tables. If the job is a transformation job, data accumulates in the staging tables but no new transformations are applied and written to your target tables.
Step 2: Modify your Pipeline Job
If you look in the SQLake catalog view at the properties of the job that you altered (highlighted in the image below), you can see the END_AT = NOW parameter has been translated into a TIMESTAMP. You use this timestamp when you recreate your modified job. But before you delete this “old” job, be sure to record the TIMESTAMP value – perhaps, for example, copying it into some external editor for reference. Depending on how significantly you must modify your pipeline logic, you may wish to copy the entire job definition to your clipboard and paste it into your SQLake worksheet so you can modify on top of what you currently have.
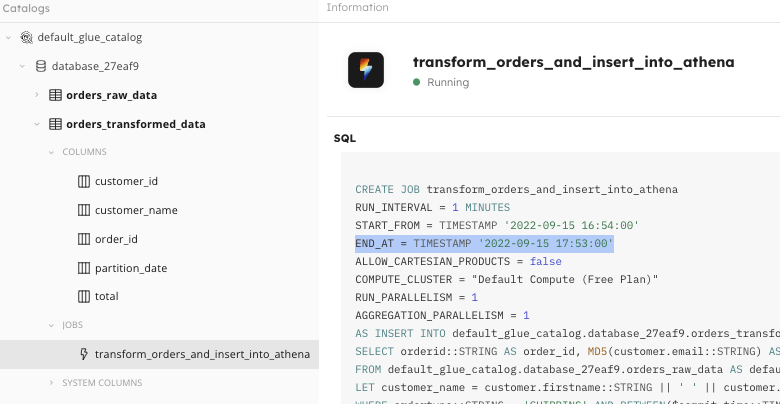
END_AT = TIMESTAMP ‘’ configuration
With the previous job configuration documented, you can now modify whatever you need within your job definition. If this is a data ingestion job, you may not need to make any modifications other than to wait for the corrected data to become available on the source. If it’s a data transformation job, you can modify your transformation SQL however you wish.
Step 3: Create your Modified Job
With your CREATE JOB statement now ready to run, verify that the START_FROM = TIMESTAMP configuration matches the END_AT = TIMESTAMP configuration from your prior job. Your CREATE JOB statement should not have an END_AT configuration, unless you know of some future time you want your job to stop. Below is a full example of a modified transformation job, displaying the START_FROM configuration timestamp taken from the earlier example.
CREATE JOB transform_orders_and_insert_into_athena_v2
START_FROM = TIMESTAMP '2022-09-18 00:00:00'
ADD_MISSING_COLUMNS = true
RUN_INTERVAL = 1 MINUTE
AS INSERT INTO default_glue_catalog.database_0d114d.orders_transformed_data MAP_COLUMNS_BY_NAME
SELECT
orderid AS order_id, -- rename columns
MD5(customer.email) AS customer_id, -- hash or mask columns using built-in functions
customer_name, -- computed field defined later in the query
nettotal AS total,
$commit_time AS partition_date
FROM default_glue_catalog.database_0d114d.orders_raw_data
LET customer_name = customer.firstname || ' ' || customer.lastname
WHERE UPPER(ordertype) = 'SHIPPING' -- use UPPER() function to normalize case of ordertype
AND $commit_time BETWEEN run_start_time() AND run_end_time();
Step 4: Delete your Previous Job
You’ve ended processing of your prior job. There is no need to delete it unless you wish either to reuse the job name or just keep your environment less cluttered. If you wish to drop the prior job, simply run the DROP JOB command:
DROP JOB transform_orders_and_insert_into_athena_v1;
When to Consider Correcting Your Output
If the historical data in your SQLake output does not need to be corrected, the process outlined above should be all you need. But if your modification also must include correcting some data in your output tables, you can use SQLake’s ability to time travel and replay data. Use a START_FROM timestamp in your modified job that references the time in the past at which you want the corrective reprocessing to start. Just enter a timestamp that goes back far enough to push corrected data to your output table.
- If your output table has a primary key specified, the new transformation job overwrites the values in the table for each key.
- If your output table does not specify a primary key, corrected data is appended to your output table.
Automating Pipeline Modifications via CI/CD
Thus far you’ve seen how to use SQLake to make manual modifications to production pipelines. In certain cases, such as ensuring that pipeline logic is managed by a version control system such as Git, you may wish to orchestrate these changes programmatically through a CI/CD process.
Upsolver SQLake provides a CLI you can call from any CI/CD solution. The CLI can execute the same SQL commands via a worksheet that you just ran interactively; you can schedule and implement any changes in an automated fashion. For more information on the SQLake CLI, consult the following documentation: https://docs.upsolver.com/sqlake/cli; or check out our article on How to Implement CI/CD for your Data Pipelines with Upsolver SQLake and Github Actions.
Summary – a Reliable Way to Change Data Pipelines in Production
It can be tricky and time-consuming to correct pipeline problems and retroactively modify pipeline output data. But it’s common to have to do it; bugs and logic changes made for business reasons are a reality. As you’ve seen in this post, SQLake makes it easy to modify production pipelines with minimal impact to your data outputs. You can try this for yourself. Sign up for a free SQLake account. In your SQLake environment, from the All Worksheets page, in the upper-right click See All Templates. Then scroll to find the Modifying Production Pipelines template.
Try SQLake for Free
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. You can try SQLake for free; no credit card required. Continue the discussion and ask questions in our Slack Community.
Published in:
Blog
,
Building Data Pipelines
