
Explore our expert-made templates & start with the right one for you.
Ad Tech: Accessing More Data, Fine-Tuning Bids
-
 Jerry Franklin
Jerry Franklin
- Use Cases
- May 11, 2021
It’s an unhappy choice: To make critical decisions about ad targeting in real-time, you’ve had to either:
- blow out your budget and spend a fortune on engineering resources; or
- risk a costly wrong move by opting not to store and process all the data you need.
But you do not have to make this tradeoff any longer. Below we explain why.
In this story:
- The challenge: High data volumes, precise low-latency decisions
- The solution: A real-time streaming architecture
- Working it: Three successful companies in action
- Summary – Real value in a real-time architecture
The challenge: High data volumes, precise low-latency decisions
Developing new technology in the online advertising space means overcoming a set of engineering hurdles. For ad tech companies, success begins and ends with matching the right ad to the right user at the right time. This often requires processing high volumes of data at millisecond latency in order for advertisers to meet revenue forecasts for their bids.
Advertising data is generated in high volumes and in real-time, and typically as a stream. A small data stream might consist of several hundred thousand events per second; a large one, an order of magnitude bigger. (An event can be anything generated by the user – a mouse click, an ad impression, a download, and so on.) Then there are the low margins – you might monetize only 1 click out of 100,000. So the ratio of data to value is skewed. Each individual data point may be worth $.000001, hence developers in this space are constantly seeking solutions to give them that slight edge over the competition.
Imprecision, meanwhile, is costly. An improperly-set bid limit, or an error in a data producer, and you could spend 6 or 7 figures for ads targeted at people who’ll never click on them.
Yet in a traditional data warehouse architecture, the only way to avoid spending lavishly on data infrastructure is to make compromises:
- You may not store all your data, nor prepare it such that your business analysts can use the analytics tool of their choice to discover insights and understand system performance.
- You avoid engineering-intensive projects such as streaming joins that otherwise would enable you to contract for additional information with third parties to enrich your existing data and refine your user profiles. That’s because such data aggregation must be coded manually, which, as you may be painfully aware, is slow, resource-intensive, and error-prone. Examples could include sentiment analysis, or associating a bid request from an ad exchange company with a customer purchase or install.
- You might shy away from developing your own user store which would have enabled you to analyze all of your information on users to create the most effective bid strategy.
The upshot is that advertisers simply don’t get the value they want and need out of all the data they have or can get.
The solution: a real-time streaming architecture
In fact, much can be automated, even simplified, at which point storing and analyzing all of the data that comes in becomes cost-effective. Compromises, such as constraining business intelligence by storing or processing only a small percentage of the data streaming in, no longer are necessary and certainly aren’t worthwhile.
While streaming architectures have typically been associated with lengthy and complex development in Apache Spark, this is no longer the case thanks to modern data lake engineering tools such as Upsolver. Upsolver provides a self-service, high-speed compute layer between your streaming data and the analytics tools of your choice. It automates menial data pipeline work, so you can focus on data enrichment, optimizing ad targeting and bid strategy, and getting the most from your ad spend.
Working it: successful AdTech companies in action
Here are real-world examples of companies benefitting from a no-compromises real-time streaming architecture:
- Storing all the data for more accurate profile analysis
- Using streaming joins and other techniques to enrich data
- Creating a user store for real-time decision making
Employing techniques such as streaming joins to enrich data
Peer39 is a leading provider of web page context data to other advertising companies that wish to enrich their own streaming data. Each day, Peer39 processes more than 17 billion events daily and analyzes more than 450 million unique Web pages holistically to contextualize the true meaning of page content.
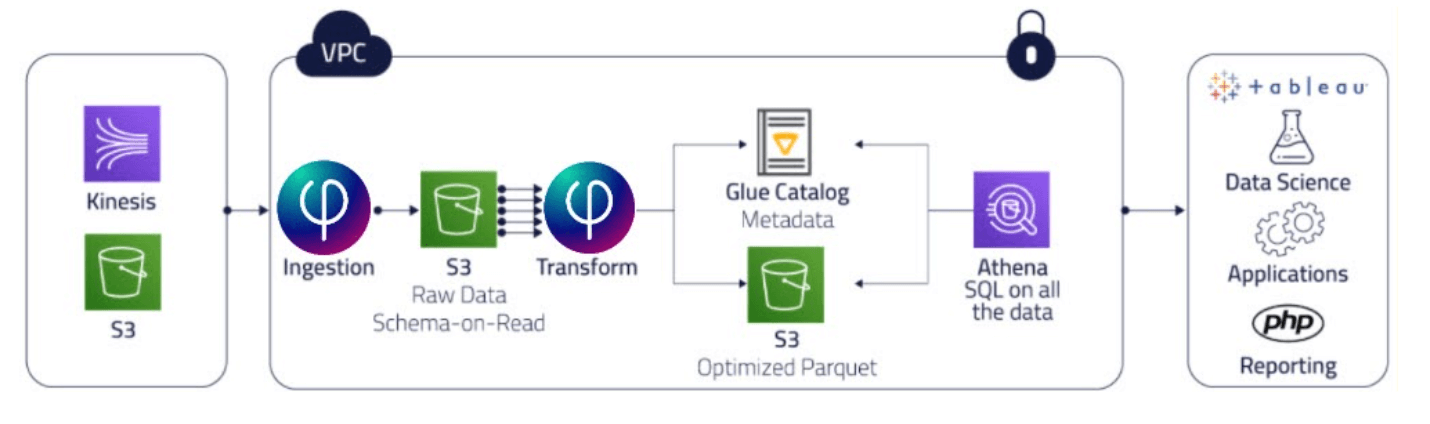
- Upsolver ingests data streamed via Amazon Kinesis.
- All of the data is stored raw in its raw format into an Amazon S3 data lake.
- Upsolver cleans, transforms, and indexes the data.
- With real-time data that’s consistent and optimized for low-latency Athena queries, business analysts and data scientists can derive insights that improve ad targeting. In this way Peer39 maximizes advertiser ROI by placing ads on the right page, in the right place, at the right time, and with the right audience.
Let’s expound on that last point. Upsolver’s data enrichment capabilities enable Peer39 to follow a chain of attribution, from purchase to install to click to impression to bid request. At every link it collects information about what happened just prior. Joining this data significantly improves bid accuracy. This isn’t feasible with Apache Spark, in which aggregating streams and configuring joins automatically involves substantial manual coding in Scala or Python.
And this was all part of Peer39’s move from an on-premises infrastructure to the cloud; they succeeded in retaining their business-critical low latency while gaining cloud elasticity and cost savings.
Creating user stores for accurate, real-time decision-making
It’s difficult when querying a data lake to achieve sub-millisecond latency results. You must serve from an online key-value store. You can do this with online databases such as Cassandra or Redis. But it’s extremely costly to maintain them and also create the necessary data pipelines.
Bigabid specializes in mobile user acquisition and re-engagement campaigns for casual gaming, social casino, dating, and productivity apps. With performance-based ads, clients only pay when new users click on the ad. Bigabid’s approach requires a unique and customized segmentation pipeline, from processing new unstructured data sources to building rich user profiles, which its machine learning models use to identify the best ad for each person – understanding current session use, how one uses the current applications, how one reacts to advertisements, and so on. The ads are identified and then served in real-time.
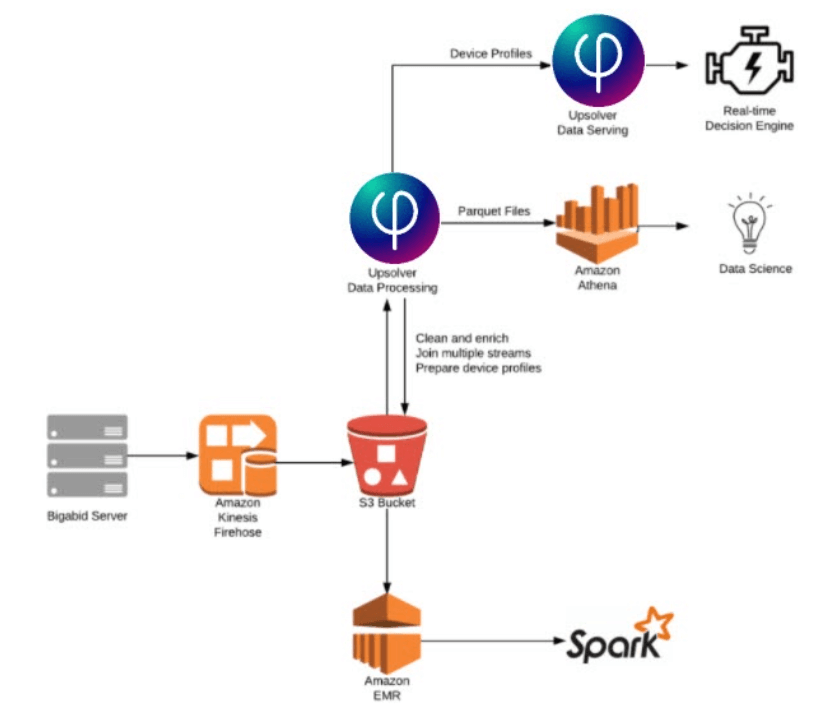
- Bigabid extracts hundreds of data points from multiple streams to account for each individual profile.
- It stores the raw data in Amazon S3.
- Upsolver enriches the data via streaming joins and prepares it to build complete user profiles in real-time.
- Upsolver also enables indexing via Parquet files, which are queried with Amazon Athena for machine learning models that match the best ad for each user.
Summary – Real Value in a Real-Time Architecture
Upsolver enables ad tech companies to create a high-performance real-time data architecture, quickly and affordably. Companies can store all of their data in an inexpensive cloud data lake, aggregate disparate data streams in real-time, and create their own user stores. On a per user basis, for millions of users, they can analyze which apps people have installed, where they’ve browsed recently, and what purchases they’ve made, and combine this with comprehensive demographic information to create insights, optimize bid targets, and make impactful decisions — all at millisecond latency.