
Explore our expert-made templates & start with the right one for you.
24 Features to Boost Your Data Movement in 2024: Part 2
-
Rachel Horder
- Building Data Pipelines
- December 24, 2023
To welcome in the New Year, we’re reflecting on some of the features we’ve built into Upsolver over the past six months that will make ingesting your data an even better experience next year – our top 24 for 2024!
We’ve reached the end of our Upsolver Feature Advent Calendar that we’ve been running on LinkedIn, so let’s look back over features 13-24. Missed features 1-12? Check them out here.
13. Transform Your In-Flight Data
14. System Insight Tables
15. Easily Pause & Resume Jobs
16. Ultra Performance for Materialized Views
17. Replication Group Jobs
18. Support for Confluent Kafka
19. Exclude Columns from Your Target
20. Faster PostgreSQL Snapshots
21. Easy Monitoring with System Tables
22. Sneaky Peek: Iceberg Support is Coming
23. New and Improved Experience
24. Replicate CDC Data to Snowflake
13 – Transform Your In-Flight Data
You can amend your in-flight data using column transformations. Transformations can be applied to the data within its column, or you can create a new column.
This is ideal if you want to mask personally identifiable information (PII) landing in your staging tables or data warehouse.
// INGEST ORDERS TO SNOWFLAKE AND MASK CUSTOMER EMAIL ADDRESS
CREATE SYNC JOB ingest_kinesis_to_snowflake
COMMENT = 'Ingest Kinesis orders to Snowflake'
START_FROM = BEGINNING
CONTENT_TYPE = JSON
EXCLUDE_COLUMNS = ('customer.email')
COLUMN_TRANSFORMATIONS = (hashed_email = MD5(customer.email), ordertype = UPPER(ordertype))
COMMIT_INTERVAL = 5 MINUTES
AS COPY FROM KINESIS my_kinesis_connection
STREAM = 'orders'
INTO SNOWFLAKE my_snowflake_connection.demo.orders_transformed;Learn how to use columns transformations in your jobs.
14 – System Insight Tables
If you want to perform bespoke queries for data observability, you can directly query the system insight tables for comprehensive statistics about columns within datasets in your catalog.
- The job output table serves as an invaluable asset for understanding the characteristics of your outputs, optimizing queries, and troubleshooting job-related issues.
- The dataset column statistics table is useful for data profiling, query performance optimization, and monitoring schema changes
Both tables are powered by Upsolver’s real-time stream processing engine.

Check out the Insights reference for further information.
15 – Easily Pause & Resume Jobs
This is one of those features that outwardly appears simple, but we’ve engineered the pausing of a job to ensure there’s no data loss when it is then resumed. You can pause and resume jobs via the user interface, or by running one simple line of SQL code.
// PAUSE WRITE JOB
ALTER JOB ingest_web_orders_to_snowflake PAUSE WRITE
SKIP_VALIDATIONS = ('DATA_RETENTION');
// RESUME WRITE
ALTER JOB ingest_web_orders_to_snowflake RESUME WRITE; 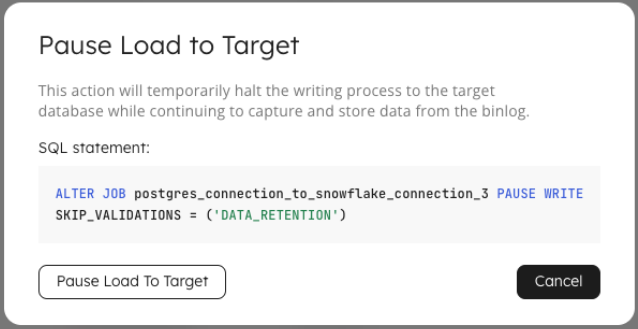
Check out the documentation for pausing and resuming your jobs.
16 – Ultra Performance for Materialized Views
When it comes to data, it’s all about performance! So to ensure your materialized views work at peak performance, you can now create a query cluster for querying your materialized views in real time.
You create a query cluster the same way as any other compute cluster and then attach it to your new or existing materialized views.
// CREATE A QUERY CLUSTER
CREATE QUERY CLUSTER my_query_cluster
MIN_INSTANCES = 1
MAX_INSTANCES = 8
COMMENT = 'Query cluster for store orders';
// CREATE A VIEW USING THE QUERY CLUSTER
CREATE SYNC MATERIALIZED VIEW default_glue_catalog.upsolver_demo.mv_physical_store_orders AS
SELECT orderid,
LAST(saleinfo.source) as source,
LAST(saleinfo.store.location.country) as country,
LAST(saleinfo.store.location.name) as name,
LAST(saleinfo.store.servicedby.employeeid) as employeeid,
LAST(saleinfo.store.servicedby.firstname) as firstname,
LAST(saleinfo.store.servicedby.lastname) as lastname
FROM default_glue_catalog.upsolver_demo.sales_info_raw_data
GROUP BY orderid
QUERY_CLUSTER = "my_query_cluster";
Furthermore, if you have an existing materialized view and create a new query cluster, you can use an ALTER statement to attach it:
ALTER MATERIALIZED VIEW default_glue_catalog.upsolver_demo.mv_web_store_orders
SET QUERY_CLUSTER = "my_query_cluster";Discover how to create a query cluster and view the full list of options, and how to create a materialized view.
17 – Replication Group Jobs
Ok, this feature may sound dull, but if you have a CDC source, we promise this will excite you! Replication group jobs are a super cool method for copying your CDC data from Microsoft SQL Server, MongoDB, MySQL, and PostgreSQL into multiple Snowflake schemas.
In the code sample below, the same data is written to a production schema AND a development schema in Snowflake. With replication groups, you can:
- Create one or more groups.
- Apply different transformations to each group.
- Send one set of tables to one schema and another set to another schema.
- Use different write modes across groups: merge one, and append another.
- Configure the freshness of the data in individual groups.
Highly efficient yet highly configurable.
CREATE REPLICATION JOB mssql_replication_to_snowflake
COMMENT = 'Replicate SQL Server CDC data to Snowflake groups'
COMPUTE_CLUSTER = "Default Compute (Free)"
INTERMEDIATE_STORAGE_CONNECTION = s3_connection
INTERMEDIATE_STORAGE_LOCATION = 's3://upsolver-integration-tests/test/'
FROM MSSQL my_mssql_connection
PUBLICATION_NAME = 'orders_publication'
HEARTBEAT_TABLE = 'orders.heartbeat'
WITH REPLICATION GROUP replicate_to_snowflake_prod
INCLUDED_TABLES_REGEX = ('orders\..*')
EXCLUDED_COLUMNS_REGEX = ('.*\.creditcard') -- exclude creditcard columns
COMMIT_INTERVAL = 5 MINUTES
LOGICAL_DELETE_COLUMN = "is_deleted"
REPLICATION_TARGET = my_snowflake_connection
TARGET_SCHEMA_NAME_EXPRESSION = 'ORDERS'
TARGET_TABLE_NAME_EXPRESSION = $table_name
WRITE_MODE = MERGE
WITH REPLICATION GROUP replicate_to_snowflake_dev
INCLUDE_SCHEMA_DEFINITION = ('orders\..*')
COMMIT_INTERVAL = 1 HOUR
REPLICATION_TARGET = my_snowflake_connection
TARGET_TABLE_NAME_EXPRESSION = 'history_' || $table_name
TARGET_SCHEMA_NAME_EXPRESSION = 'ORDERS_DEV'
WRITE_MODE = APPEND;To learn how you use replication groups to ingest your CDC data to Snowflake, check out the documentation and read the how-to guide, Replicate CDC Data to Multiple Targets in Snowflake.
18 – Support for Confluent Kafka
Confluent Cloud harnesses the power of a fully managed, scalable, event-streaming platform, enabling seamless integration and real-time processing of data across your applications and systems.
Upsolver has partnered with Confluent to enable you to ingest your real-time, high-volume application data into Snowflake and the data lake.
CREATE SYNC JOB ingest_kafka_to_snowflake
COMMENT = 'Load orders into Snowflake'
CONTENT_TYPE = JSON
COMMIT_INTERVAL = 5 MINUTES
AS COPY FROM CONFLUENT upsolver_kafka_samples
TOPIC = 'orders'
INTO SNOWFLAKE my_snowflake_connection.demo.orders_transformed;Create a job to ingest your data from Confluent Kafka.
19 – Exclude Columns from Your Target
Super easy to apply to your jobs, the EXCLUDE_COLUMNS option tells Upsolver to ignore data in the columns you specify, and the columns are not created on the target. Simply specify a single column, a list of column names, or use a glob pattern. Use this option to:
- Save storage space by excluding extraneous data.
- Maintain a clean data structure.
- Protect private data by excluding columns with sensitive information.
- Control the width of the target table by managing how many columns are created if your target system has a limit on the number of columns it supports, and continuously adding columns can cause issues.
Small feature, BIG impact. Love it!!
// INGEST ORDERS FROM KAFKA TO SNOWFLAKE
CREATE SYNC JOB ingest_and_tranform
COMMENT = 'Load raw orders from Kafka and transform and exclude data'
CONTENT_TYPE = JSON
// Exclude the original email column
EXCLUDE_COLUMNS = ('customer.email')
// Mask customer email into new column to hide PII
COLUMN_TRANSFORMATIONS = (hashed_email = MD5(customer.email))
AS COPY FROM KAFKA upsolver_kafka_samples
TOPIC = 'orders'
INTO SNOWFLAKE my_snowflake_connection.demo.orders_transformed;20 – Faster PostgreSQL Snapshots
To speed up the time it takes to get data flowing from your PostgreSQL databases, we now exclude tables that are not part of the publication from the snapshot. This means that if you have 100 tables in your database, and only 57 are included in the publication, the other 43 will be ignored.
We use Debezium to handle the snapshot and ongoing stream of events and, when it first connects to your database, it determines which tables to capture. By default, all non-system table schemas are captured, so by reducing this to only include the tables in the publication, your data will be streaming into your target faster.
Learn more about Performing Snapshots in Upsolver.
21 – Easy Monitoring with System Tables
Run queries against the built-in system tables to uncover information about the entities in your organization. Updated in real time, these details provide properties and status information, along with creation and modification dates. Dig into the system tables to discover configuration information for:
- Clusters: View a list of the clusters in your organization, including the size, IP addresses, and description.
- Columns: See all columns across your tables and column properties to help diagnose data quality and integrity issues.
- Connections: Check out your source and target connections, and which users created and modified them.
- Jobs: Look at your jobs for status, creation and modification date, type (ingestion or transformation), and source and target.
- Tables: List your tables and properties, check when the schema of the table last changed, as well as compaction and storage options.
- Users: View a list of all users that have access to your organization.
- Views: Query the materialized views created in your organization, including properties and schema details.
Learn how to query the system tables to view the configuration properties of your entities.

22 – Sneaky Peek: Iceberg Support is Coming
The popular open-source table format, Apache Iceberg, is a game-changer for handling high-scale data. With support for ACID transactions, time travel, and incremental processing to name a few, it’s easy to see why Iceberg is changing the data landscape.
And it’s coming to Upsolver very soon! We’re calling this one the “easy button” for Iceberg tables… Upsolver’s Senior Solutions Architect Jason Hall recently gave us a quick preview of what’s coming.
Oh, and Upsolver handles compaction, partitioning, automated retention, upserting, and schema evolution. I think it’s going to be a super cool 2024 with this feature.
23 – New and Improved Experience
Our mission here at Upsolver is to make big data ingestion really easy. Our engineers have been working super hard this year to continuously improve the Upsolver UI, ensuring you move your data from source to target with the least amount of friction. Some of the enhancements we have made to make it the possible experience for you include:
- Jobs – quickly see the status of your jobs, number of events written over time, and pause and resume jobs. You can also filter jobs by status to zoom in on those needing attention.
- Wizard – your no-code option for building pipelines has been given an uplift to make it quicker to get your pipelines following with ease.
- Datasets – we’ve built in data observability as standard so you can continuously monitor the freshness, volume, schema, quality, and lineage of your data.
- Worksheets – now accessible from the menu, your worksheets are easier to find so you can quickly jump into your SQL code.
- Menu – our new look menu makes it super easy to access resources, help, and organizations.
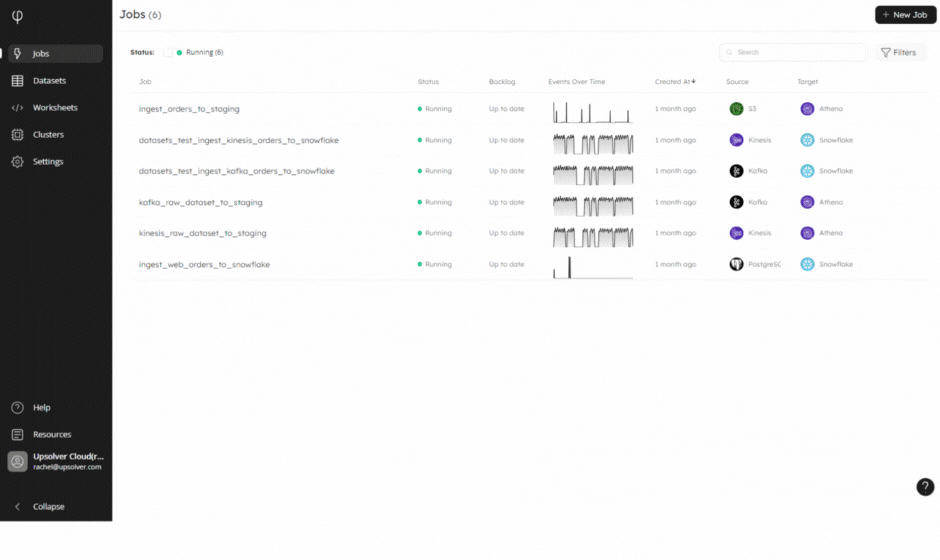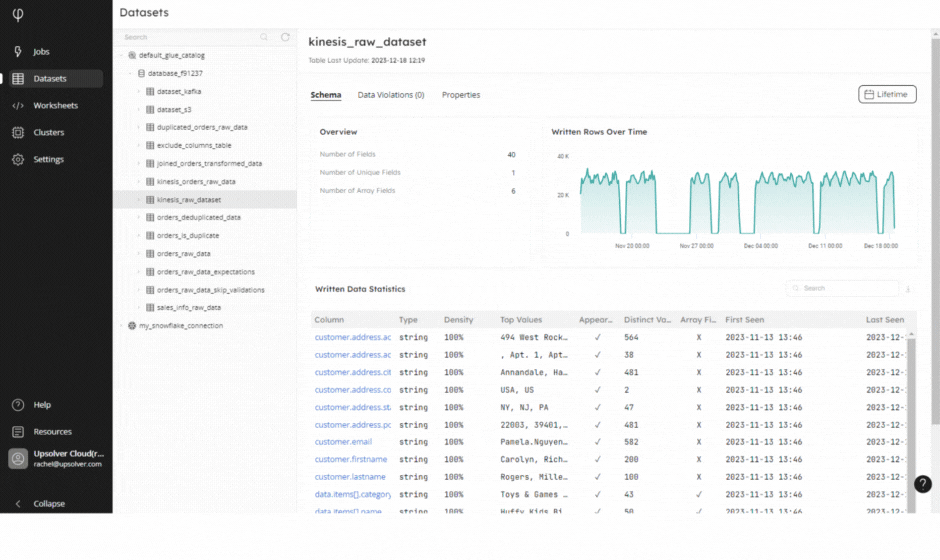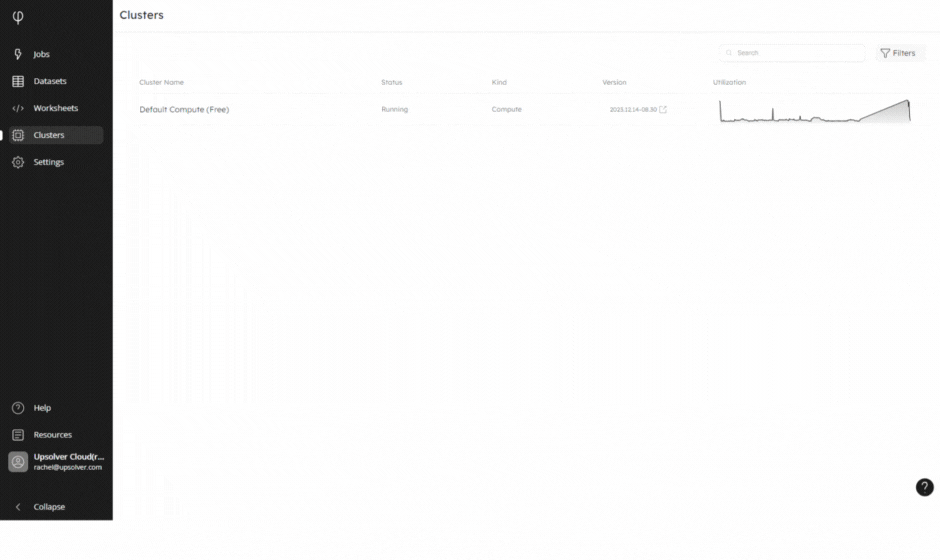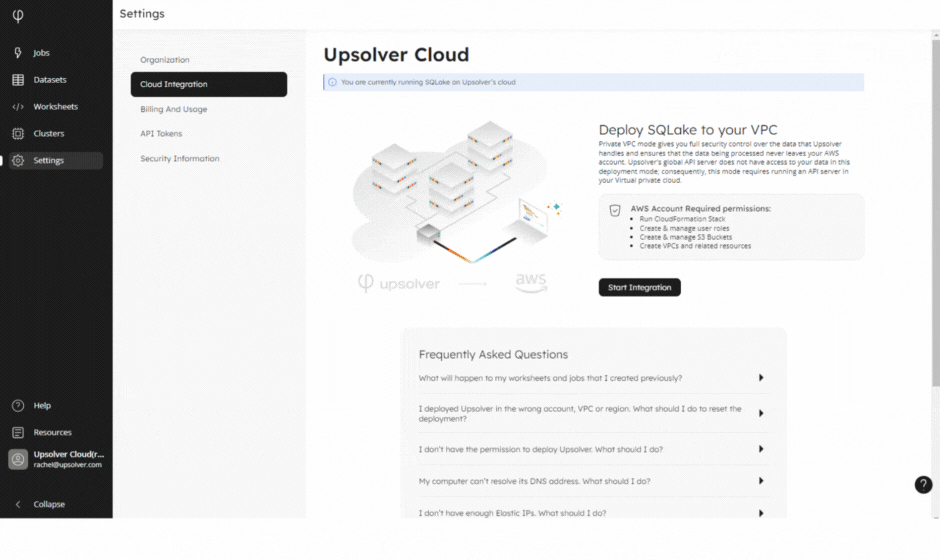
Login to your Upsolver account or create your free 14-day trial to experience our new and improved IDE.
24 – Replicate CDC Data to Snowflake
Upsolver provides the ability to write one job template that generates a dedicated ingestion job for each table within your PostgreSQL and MySQL replication. This time-saving feature is super helpful when you have a large number of tables, removing the need to manually write and manage a job for each table. Upsolver will automatically create each table in Snowflake and manage schema evolution.
To achieve this, create a staging table to ingest your CDC data, then create a master job that will create the sub-jobs. Your master job will include a placeholder – we’re using {UPSOLVER_TABLE_NAME_MyDemo} in the example below – that instructs Upsolver to use each table name from the staging table as the target in Snowflake. In this example, all tables are in the orders schema, but optionally you can provide a placeholder for each schema name too. Then when your jobs are streaming, you can use built-in tools to monitor your jobs and observe your data.
// CREATE A MAIN JOB THAT GENERATE A SUB-JOB FOR EACH TABLE
CREATE SYNC JOB postgres_to_snowflake_output
RUN_INTERVAL = 5 MINUTES
CREATE_TABLE_IF_MISSING = true
ADD_MISSING_COLUMNS = true
AS MERGE INTO SNOWFLAKE my_snowflake_connection.orders.{UPSOLVER_TABLE_NAME_MyDemo} AS target
USING (
SELECT *,
$is_delete::BOOLEAN AS UPSOLVER_IS_DELETE_MyDemo,
COALESCE($primary_key::STRING, UUID_GENERATOR('')) AS UPSOLVER_PRIMARY_KEY,
$event_time::STRING AS UPSOLVER_EVENT_TIME,
UPPER($table_name) AS UPSOLVER_TABLE_NAME_MyDemo
FROM default_glue_catalog.upsolver_samples.postgres_to_snowflake_staging
WHERE $event_time BETWEEN RUN_START_TIME() AND RUN_END_TIME()
) AS source
ON source.UPSOLVER_PRIMARY_KEY = target.UPSOLVER_PRIMARY_KEY
WHEN MATCHED AND UPSOLVER_IS_DELETE_MyDemo THEN DELETE
WHEN MATCHED THEN REPLACE
WHEN NOT MATCHED THEN INSERT MAP_COLUMNS_BY_NAME;Follow our guide to Replicate CDC Data to Snowflake using the master/sub-jobs code.
If you have high-scale big data, streaming, or AI workloads, try out Upsolver’s self-serve cloud data ingestion service FREE for 14 days or book a demo with of our expert solution architects.
Published in:
Blog
,
Building Data Pipelines