Explore our expert-made templates & start with the right one for you.
Build data lake analytics at the speed of adtech
In adtech you have to run fast to win.
With Upsolver you can build streaming analytics in days.

We make data lakes easy
Upsolver was built from the ground up to simplify data lake engineering.
The low cost of a data lake makes it attractive for all sorts of analytics workloads. This is especially true for adtech use cases, where the speed and scale drives significant cost. But data lakes have been notoriously difficult to engineer, requiring hand-coding and complex configuration.
Upsolver’s no code data lake engineering platform shields you from the complexity of the data lake. Anyone with some SQL knowledge can build, test and deploy an analytics pipeline in days. Compare this to the months required to hand code, debug and deploy data lake jobs using Spark, Scala and Airflow.
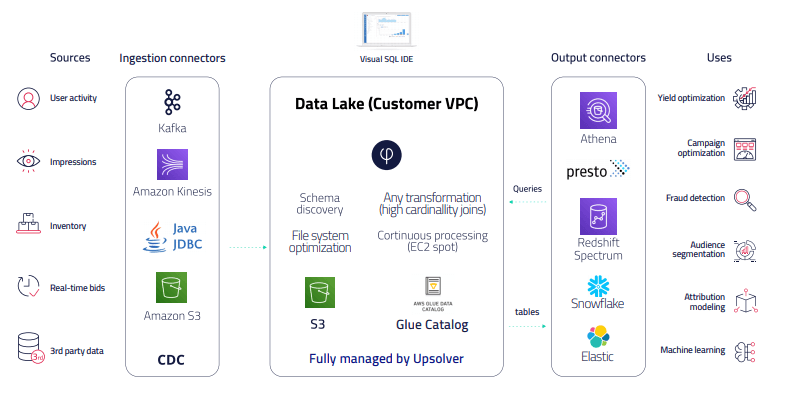
Upsolver main features include:
- A Visual SQL IDE for designing pipelines and transformations. Switch seamlessly between drag-drop UI and editing SQL operations.
- Drag-drop streaming ingestion via native connectors like Kafka and Kinesis, plus schema-on-read detection.
- Drag-drop output to query engines & data stores – connect to query engines like Athena and Presto, or output to data stores like Redshift, Snowflake, or Elasticsearch.
- Continuous joins on high cardinality data, plus any other transformation you can imagine.
- Upserts on your data lake – maintain data consistency via queryable views that are kept up-to-date through on-going compaction, but also allow for replay using the raw data.
- Automatic performance best practices for data lakes – we’ve incorporated recommended performance optimizations as code – things like file formats, partitioning, compaction – so you can focus on analytics.
- Millisecond access – get extremely fast direct query access using Lookup Tables, our built-in decoupled key-value store.
Born in adtech, Upsolver was built to handle unique speed and scale
Adtech may be the most data intensive industry out there and we were built to address those requirements such as trillions of rows, millions of events per session, and high cardinality data sets.

You have to run fast, and we add agility to your data engineering
Upsolver lets you build analytics in days, with no complex coding or configuration. We’ve automated the things that make data lake engineering hard so that you can use native connectors, drag-drop operations and SQL to build your analytics pipelines.

Margins matter, so we minimize the cost of your data lake
Your cloud data lake holds the promise of affordable analytics. Upsolver unlocks that value by making your data lake perform like your data warehouse at a fraction of the cost.

See how Upsolver addresses your use case
Audience segmentation
Audience segmentation through cluster analysis is critical to successful advertising operations. Upsolver offers the affordable speed and scale to maintain up-to-date structured data for interactive analysis and populating dashboards. In particular it can continuously join live impression data with user attributes.
Campaign performance
Optimizing campaigns requires continual analysis of a large number of dimensions, from advertising impressions to user behavior data (advertising, purchase and other), media site data and user demographics.
Real-time machine learning
Machine learning is being applied to support intelligence advertising placement. Key to machine learning is the feature store, which holds the catalog of features that can be applied to any ML model. Maintaining a real-time feature store requires fast transformations on large, streaming data sets. Upsolver is uniquely suited for acting as a performant yet affordable feature store hosted on S3.
Click fraud detection
Click fraud is a big deal in programmatic advertising. Upsolver can simplify building real-time pipelines that detect likely bot activity as it happens, allowing the system to disable the user from being served ads, minimizing fraud. This requires analyzing high cardinality streaming data quickly at which Upsolver is expert.
Analytics democratization
With Upsolver any data consumer who knows SQL can build analytics workloads quickly, without writing code or configuring distributed systems like Spark. Advertising operations and business analysts can unlock the data in their lake and break the bottleneck caused by overloaded big data engineering teams.