

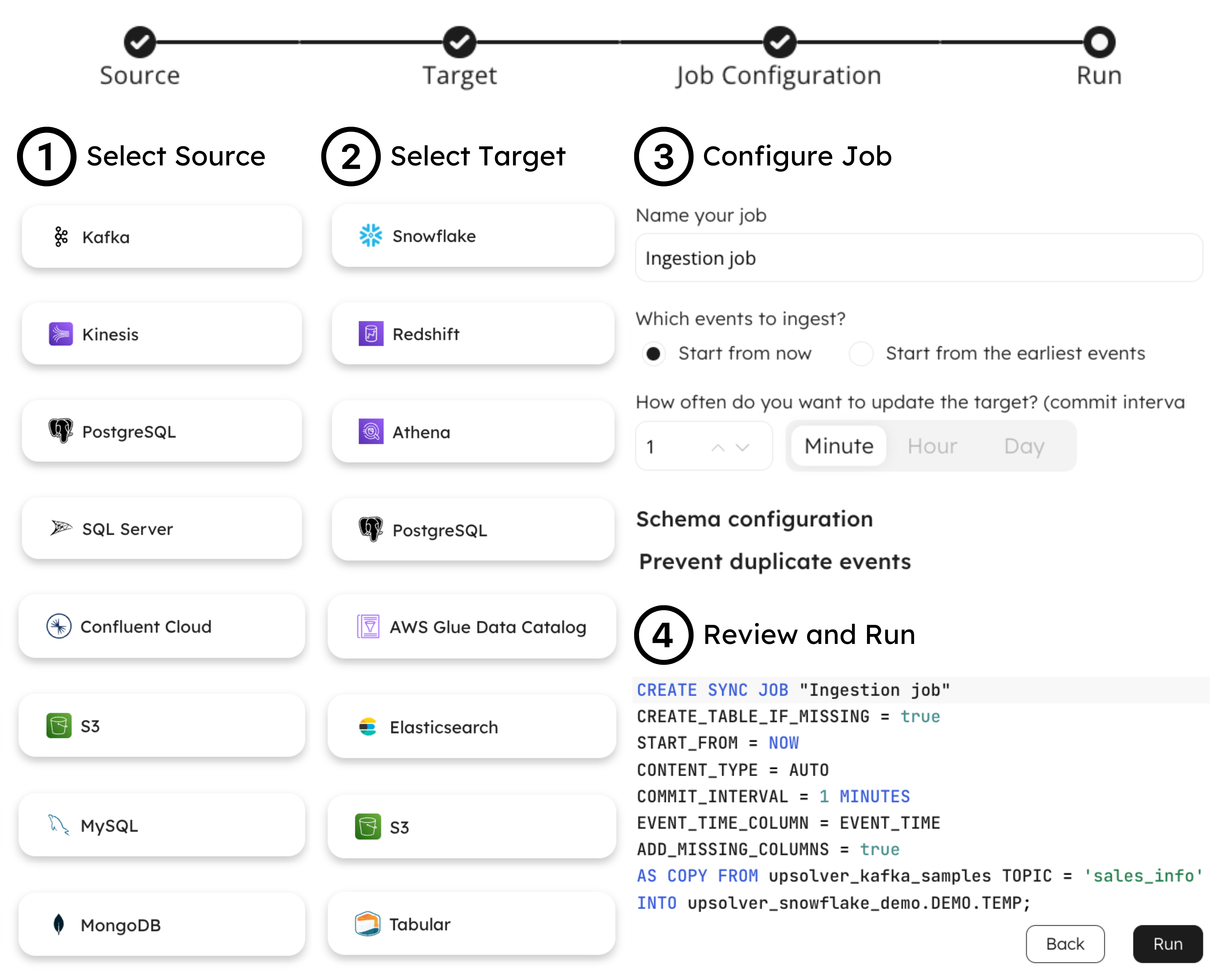
Explore our expert-made templates & start with the right one for you.

Easy button for high-scale data ingestion
Empower software engineers to prepare and deliver the most complex application data for analytics & AI, in minutes! Enjoy the cost savings and scale of a cloud-native Lakehouse on AWS, without the engineering pain.
27 Trillion rows
ingested/month
50 PB
managed/month
35 GB / sec
peak throughput
Open data from ingestion to query
Warehouse-like capabilities and performance without vendor lock-in or complex engineering workflows
Your teams enjoy shared access to synchronized data from live sources in their analytics and ML targets, from their tool of choice. In the background, we run optimizations and cleanup to keep your costs down.

Optimize Iceberg anywhere
Reduce costs and accelerate queries for Iceberg without managing bespoke optimization jobs
Our Iceberg Table Optimizer continuously monitors and optimizes Iceberg tables, those created by Upsolver and those created by other tools.

Identify waste in your existing AWS-based Iceberg lake and get an immediate performance boost.

Or, build your first Iceberg lake with Upsolver. Fully-optimized and observable from the start.

Real-time data replication
Give your business an edge with up to the minute data! Easily ingest data from operational stores to the warehouse and Iceberg lake with minimal configuration and automatic table maintenance and optimization.
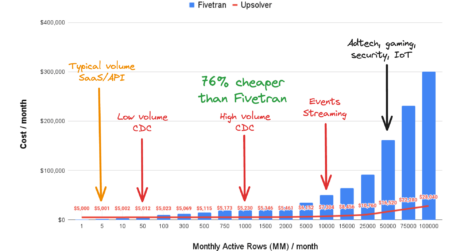
High-volume connectors
Our source and destination connectors are built with scale in mind, offering the most reliable, fast and cost-effective replication solution for production systems, including databases and message queues.
Change data is merged in the lake with continuous adaptive optimization, ensuring peak query performance for downstream users at all times.


Unified data
Unified dev experience
Upsolver matches your development style and gives you the tools you need to ensure quality, on-time data.

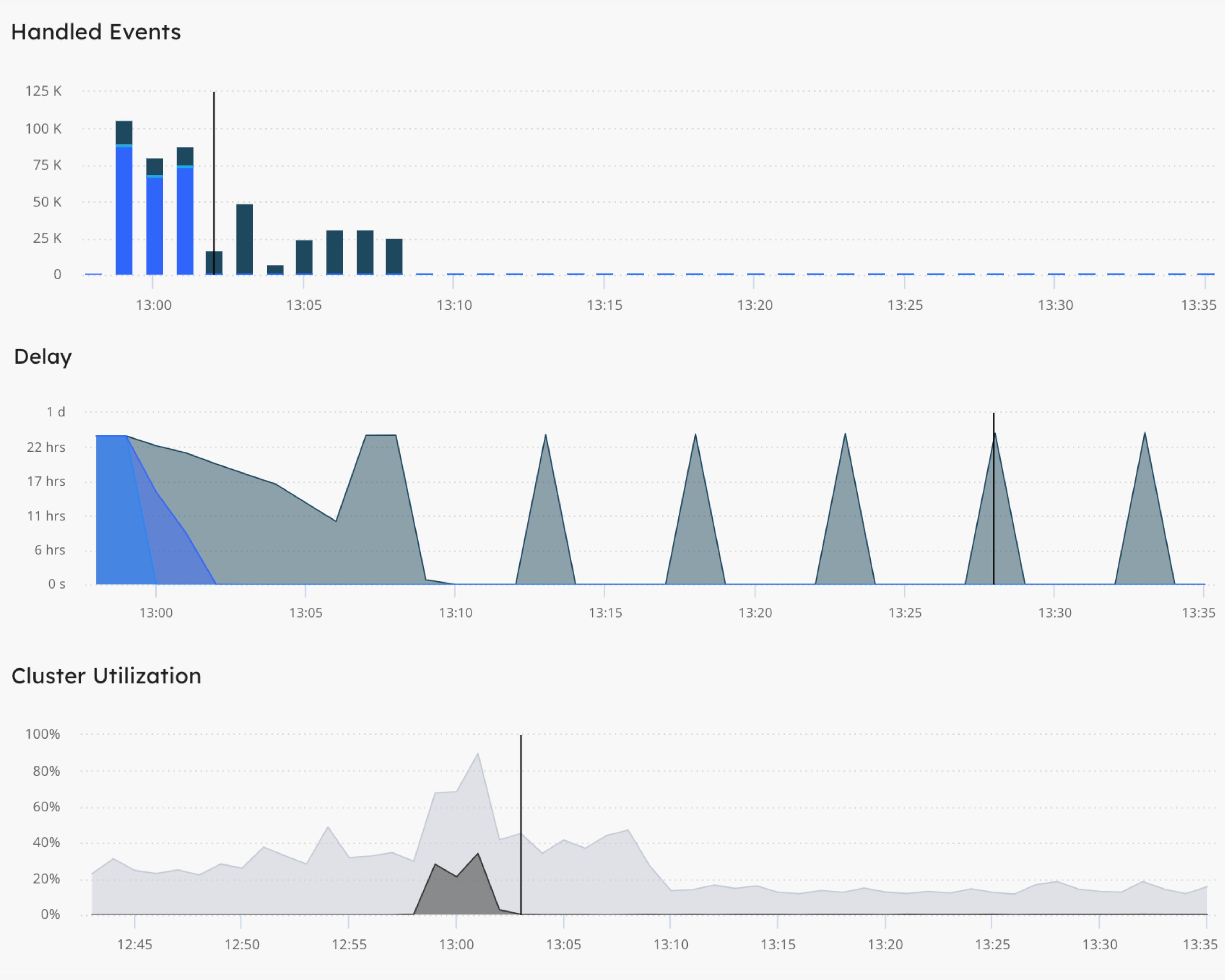

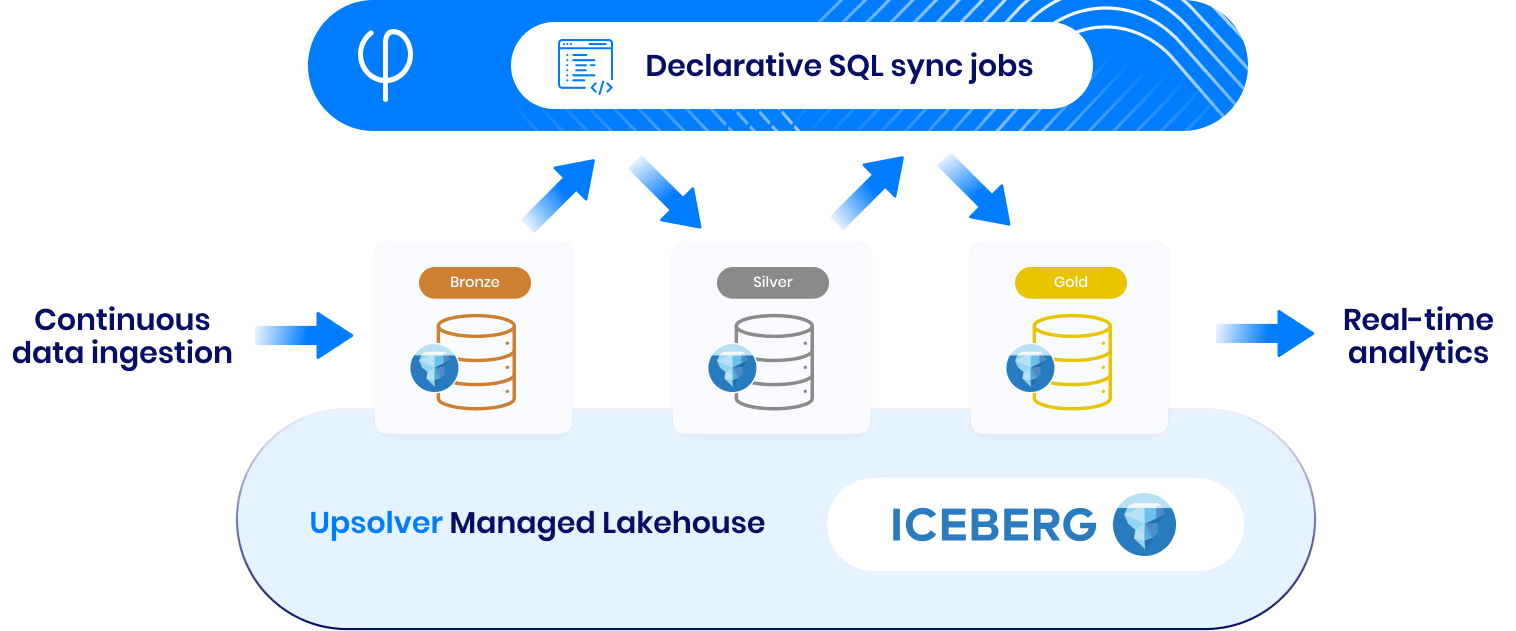

Resiliency without compromise

SyncStream technology
Synchronized pipelines ensure consistent and reliable processing of real-time events, with late-arriving events automatically accounted.

Exactly-once delivery
Automatically deduplicate events over large windows of time, at scale. Works with streams and files without compromise.

Data replay and backfill
Data use cases outgrow the current view of the data. Time travel and replay data from any point in history, or create jobs to backfill tables.

Handling schema drift
Upstream applications add, remove, rename, and type-change columns. Upsolver automatically adapts to evolving schema, even nested ones.

Managed scaling
Built on a decoupled shared-nothing architecture, Upsolver scales seamlessly to match usage, utilizing EC2 Spot instances to reduce cost.

Autohealing
Systems are unpredictable. In case of network downtime, Upsolver automatically reconnects and restarts operations where it left off.
Empowering the next generation
of data developers
From startups to enterprises


