Explore our expert-made templates & start with the right one for you.
Reference architecture comparison
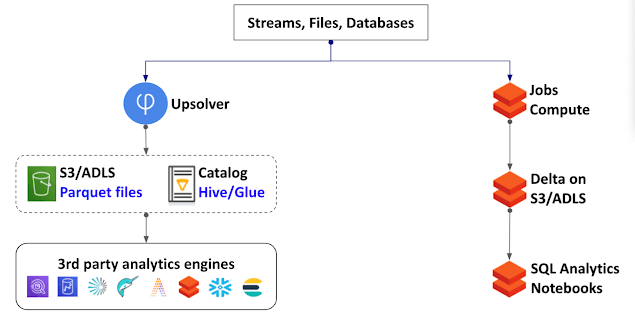
Upsolver and Databricks are two choices to consider platforms for building and running continuous workloads on your data lake. In this page we will highlight the advantages of each and how they relate to various use cases.
Databricks Jobs Compute is a data lake processing service that competes directly with Upsolver. Databricks SQL Compute is a query service that can query Upsolver tables. Databricks Notebooks can also run against Upsolver tables.

Accelerate data lake queries
Real-time ETL for cloud data warehouse
Build real-time data products
Explore our expert-made templates & start with the right one for you.