Explore our expert-made templates & start with the right one for you.
Drastically Lower Cloud Compute and Data Engineering Costs
Converting complex and streaming raw data into analytics ready tables can get very expensive, especially at big data scale. You have to pay for storage and compute to ingest, store and transform the data. You have to pay for software to build and run the pipeline, from data integration tools to data processing and orchestration services. Last but not least, you must utilize skilled data engineers and cloud ops professionals to build and maintain these pipelines.
Upsolver helps you drastically lower all of these costs.
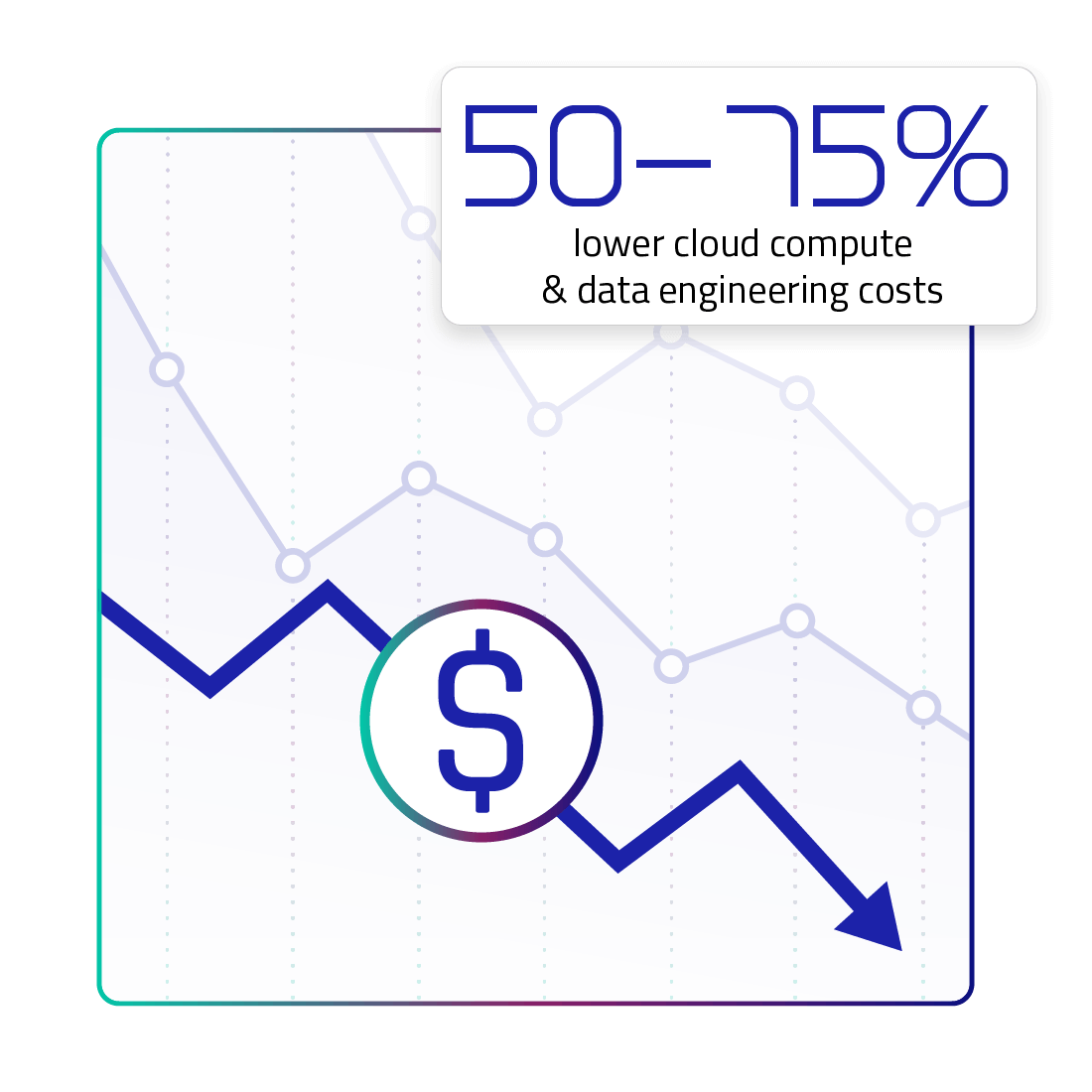
Less compute and lower cost
Upsolver harnesses the attractive economics of stream processing on Spot instances with long term storage on S3 or ADLS.
Incremental stream processing reduces the total compute required compared to RAM-intensive batches.
Spot instances reduce the cost per compute unit. This is substantially less expensive than running these jobs on your cloud data warehouse.
Lower Software Costs
Upsolver eliminates the need for several types of software purchases.
- No need to pay for managed Spark for these jobs, reducing your overall Spark spend.
- No need to pay for orchestration tools for these jobs.
- No need to pay for managed ingestion services to bring in streaming, batch or CDC data.
- No need to pay for a 3rd key-value store like Cassandra or Redis for stateful transformations.
Lower Personnel Costs
Data engineers are scarce and precious. By requiring only SQL knowledge, and automating pipeline engineering tasks such as compaction, orchestration and more, Upsolver makes your data engineers 10X more productive and enables them to offload repetitive data pipeline requests to data consumers. This means they spend far less time on building pipelines and more time on advanced projects.
As a managed service running in your VPC, Upsolver also relieves your cloud ops team of deploying, monitoring and maintaining your Upsolver instance.









Explore Upsolver your way
Try SQLake for Free (Early Acce
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience.
Talk to a Solutions Architect
Schedule a quick, no-strings-attached with one of our cloud architecture gurus.
Customer Stories
See how the world’s most data-intensive companies use Upsolver to analyze petabytes of data.
Integrations and Connectors
See which data sources and outputs Upsolver supports natively.