Explore our expert-made templates & start with the right one for you.
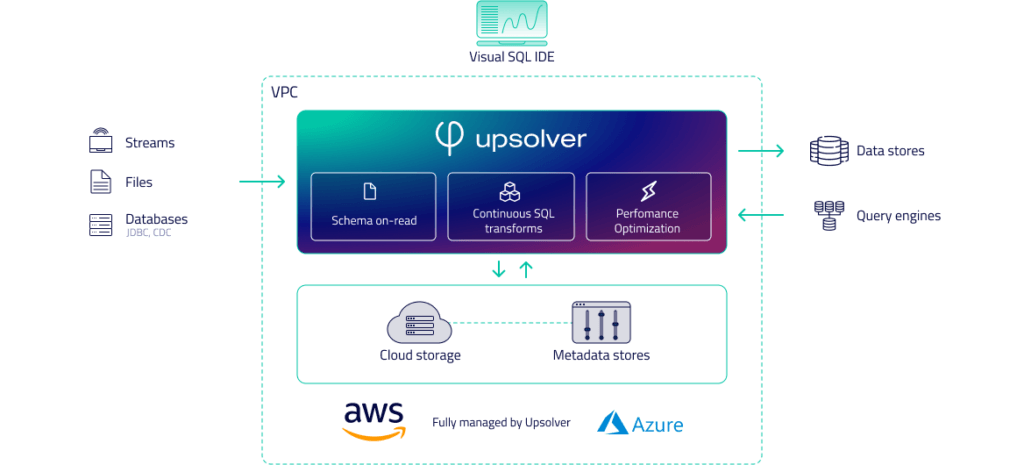
The quickest path from streams
to analytics-ready tables.
Easily and affordably transform streaming data into live tables on top of cloud object storage. Query directly on the lake or continuously output tables to external analytics systems.
Agile
self-service data engineering
Affordable
cloud analytics
Powerful
stateful operations on data streams at scale.
70%-90%
reduction in time spent on ETL work
50%-75%
reduction in cloud data warehouse costs
TB to PB
of data in motion with billions of join keys.
What makes Upsolver different?
Lowest compute costs
Efficient EC2 or Azure utilization via Spot instances.
Smaller cloud instance via unique compression
Upsolver processes 10X more data in a given RAM footprint.
Stateful transformations in SQL
Use our Visual SQL IDE to build your pipeline, while we automate orchestration, compaction and other ugly plumbing.
Query any way you like
Get live tables that can be queried on the lake, or easily output to other systems.
Open file formats
Tables are stored in an open format – no vendor lock-in.
Key Features
Click-to-connect data sources
Native ingestion from streams, files and databases.
Upsolver makes it easy to ingest data with native connectors to:
- Event streams such as Apache Kafka, Amazon Kinesis and Azure Event Hub
- File systems on cloud object storage such as Amazon S3, Google Cloud Storage or Azure Storage
- Databases such as MySQL via log-based change data capture (CDC).
Regardless of the source, Upsolver continuously stores a raw copy of the data for lineage and historical replay, while generating and outputting consumption-ready tables based on your desired transformations

Click-to-connect outputs
Serve live tables for lake query engines and cloud data warehouses.
Upsolver creates query-ready live tables for analytics using:
- Data lake query engines such as Amazon Athena, Dremio or Apache Presto, Redshift Spectrum and Databricks
- External data stores such as Redshift, ElasticSearch or Snowflake
- Stream processing engines such as Amazon Kinesis or Apache Kafka for further transport and downstream processing.
In all cases, Upsolver allows you to select and configure the output visually.

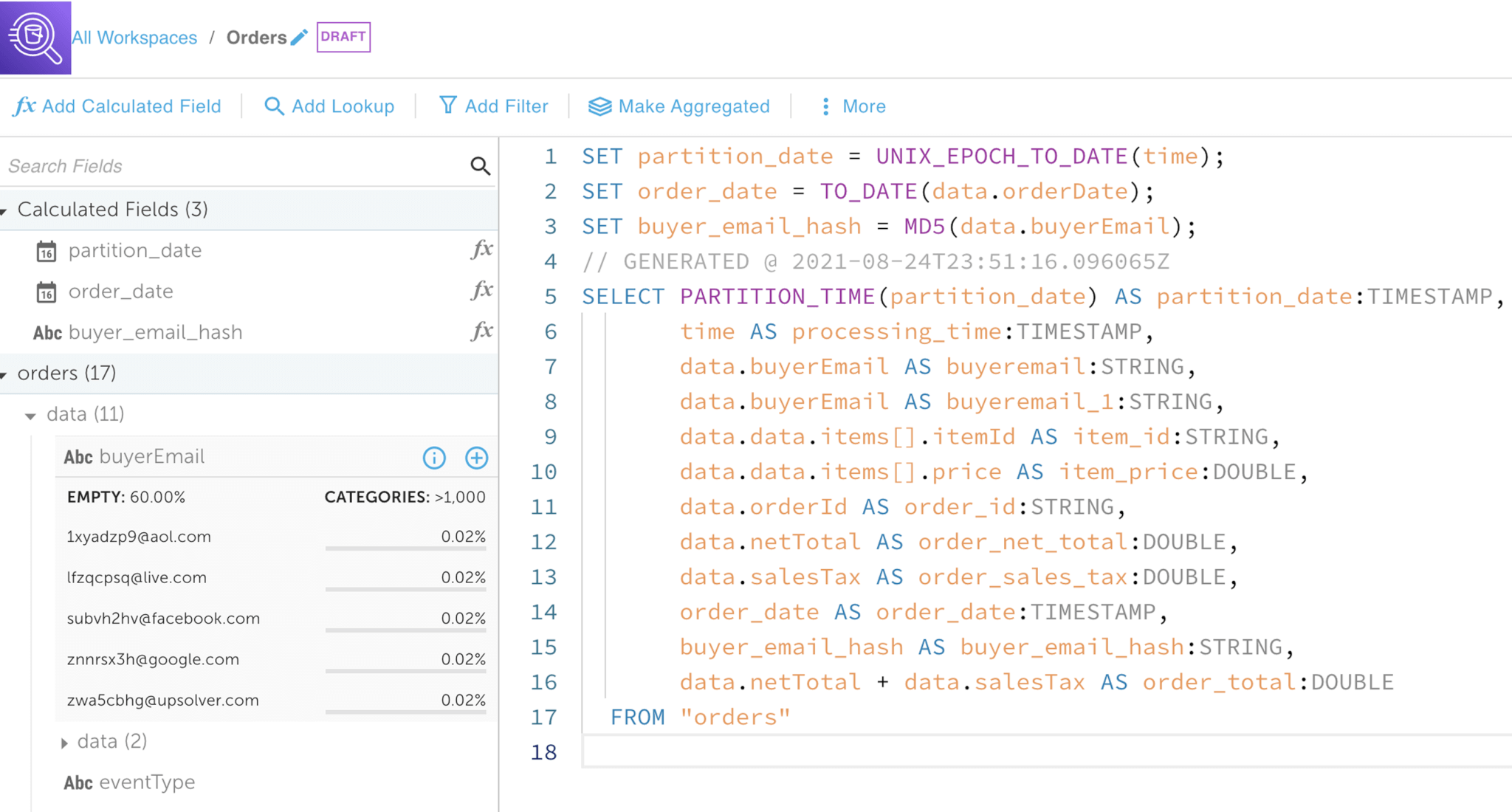
Build pipelines easily
Use SQL and a visual IDE
Upsolver provides a visual SQL-based interface so that transformation pipelines can be built without coding and hundreds of configurations in Spark/Hadoop:
- Fully featured SQL language for pipelines including support for high cardinality joins, aggregations, sliding time-windows and upserts
- Auto-generated schema-on-read and data profiling
- Automatic orchestration from SQL transformation code including separation into sub-tasks, creation of supporting indices, compaction, vacuuming, scaling and error recovery
- Replay from previous state
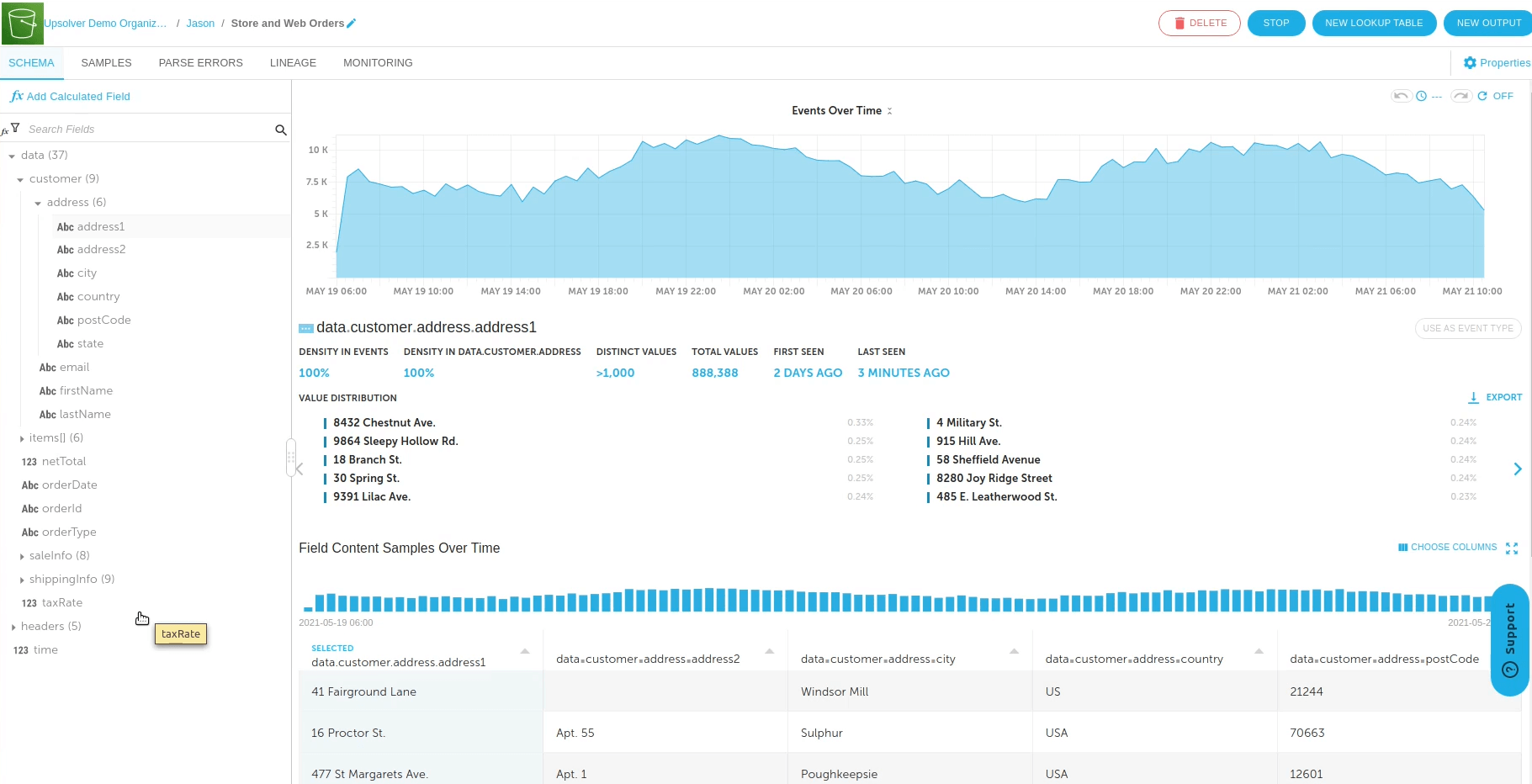
Automated table management and optimization
100X faster queries on data lake tables without ugly data plumbing
Cloud object storage has traditionally required an inordinate amount of manual configuration and tuning to deliver performance.
Upsolver automates the management and optimization of output tables so that data engineers only need to specify their transformations visually or in SQL, including:
- Various partitioning strategies
- Conversion to column-based format
- Optimizing file sizes (compaction)
- Upserts and deletes
- Vacuum stale and temporary files
- Workflow orchestration
10X price/performance for stateful streaming pipelines using breakthrough deep technology
Upsolver started as an internal project for accelerating our own analytics engineering work over AWS S3. We were frustrated by the convoluted and expensive process of building stateful streaming pipelines using Apache Spark, Airflow and Cassandra for large states.
So we built the world’s first fully decoupled key-value store called Lookup Tables which are computed using streaming SQL on multiple sources of streaming and batch data. It only stores data on cloud object storage and in-memory and it gets 10X more data in a given RAM footprint compared to Cassandra. Under the hood, Lookup Tables are based on a new file format and compression algorithm which combine efficient columnar compression with millisecond key-based queries.
Enterprise-ready
Upsolver is built for companies that run on data.
Upsolver has everything you need to implement continuous, at-scale, production pipelines. You can monitor flows, manage pipeline changes methodically, and deploy in your Cloud account or ours.
- Monitoring
- CI / CD
- Flexible deployment in private VPC or fully-managed
- SSO with role-based access control (RBAC)
Explore Upsolver your way
Community Edition
Upsolver is free to use for smaller workloads. Start instantly on the Community Edition with no credit card required.
Talk to a Solutions Architect
Schedule a quick, no-strings-attached with one of our cloud architecture gurus.
Customer Stories
See how the world’s most data-intensive companies use Upsolver to analyze petabytes of data.
Integrations and Connectors
See which data sources and outputs Upsolver supports natively.