Explore our expert-made templates & start with the right one for you.
Free Guide
Apache Kafka and the Advantage of a Real-Time Data Lake Architecture for Analytics
What is the real-time data challenge and how does Apache Kafka and data-lake architecture solves it? Read our guide to find out.
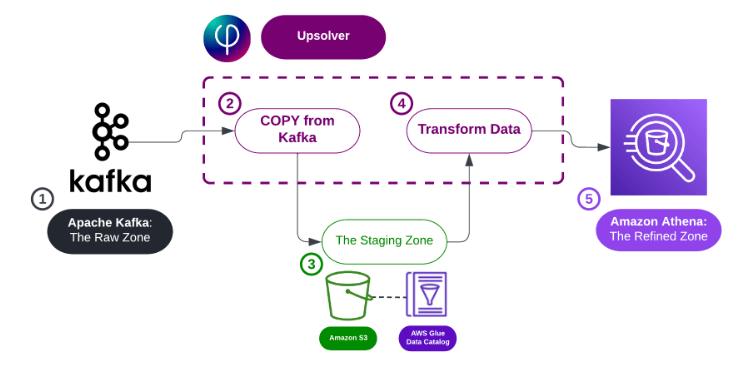
Apache Kafka is a cornerstone of many streaming data architectures – but what’s the next step? How do you build effective ETL flows, manage data and create scalable pipelines from Kafka to analytical tools?
Download our free paper and learn about:
1) Reading directly from a Kafka cluster.
2) Introducing a data lake as an intermediate stage.
3) Declarative Data Pipelines principles
4) How Upsolver can facilitate handling with Apache Kafka
Get the eBook
Thanks for signing up! Read the eBook here:
Open eBook
This guide is for:
- Data engineering leaders who want to understand how to solve practical security and privacy challenges on cloud data lakes
- CIOs who want to ensure their organization is compliant and reduce operational risks
- CTOs who want to discover cloud architecture best practices
Powering data lakes for data-intensive companies
