Explore our expert-made templates & start with the right one for you.
Webinar + Benchmark Report
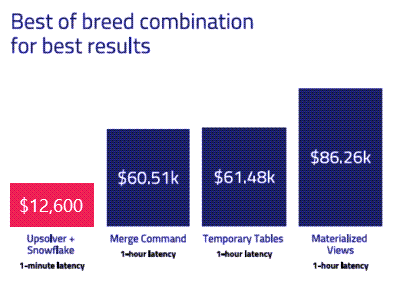
Benchmark: Continuous Data in Snowflake with and without a Data Lake
Watch On-Demand
Watch our webinar for a glimpse at our latest benchmarking tests showing dramatic cost and performance differences when processing streaming data in Snowflake.
Upsolver recently evaluated the speed and cost of various approaches to processing data for Snowflake. In this online talk, CEO & Co-founder of Upsolver, Ori Rafael, covers the following topics:
What will you learn in this webinar?
– Discuss the pros and cons of various data pipeline architectures, such as ETL and ELT
– Cover the details of the benchmark methodology and results
– Consider the implications for making architecture decisions for your modern data stack
Watch On-Demand
While cloud data warehouses have modernized how companies work with batch data, continuous data processing — whether streams or frequent mini-batches — presents challenges. This leaves businesses to trade off across 3 dimensions – cost, scale, and data freshness.
Additionally, the complexity of data integration combined with the workflow mapping required to transform complex semi-structured data types like JSON nested arrays adds unneeded overhead that even the best data engineering teams can struggle to wrangle.
Join our webinar to understand how complex data drives up the cost of cloud data warehousing, and how data lake pipelines can help you design more efficient infrastructure.
Powering data lakes for data-intensive companies
