Explore our expert-made templates & start with the right one for you.

Ingest, transform, and observe
your most complex data
Optimized open data from ingestion to query
Warehouse-like capabilities and performance without vendor lock-in or complex engineering workflows
Your teams enjoy shared access to synchronized data from live sources in their analytics and ML targets, from their tool of choice. In the background, we’re running optimizations and cleanup to keep your costs down.

Optimize Iceberg Anywhere
Reduce costs and accelerate queries for Iceberg without managing bespoke optimization jobs
Our Iceberg Table Optimizer continuously monitors and optimizes Iceberg tables, those created by Upsolver and those created by other tools.

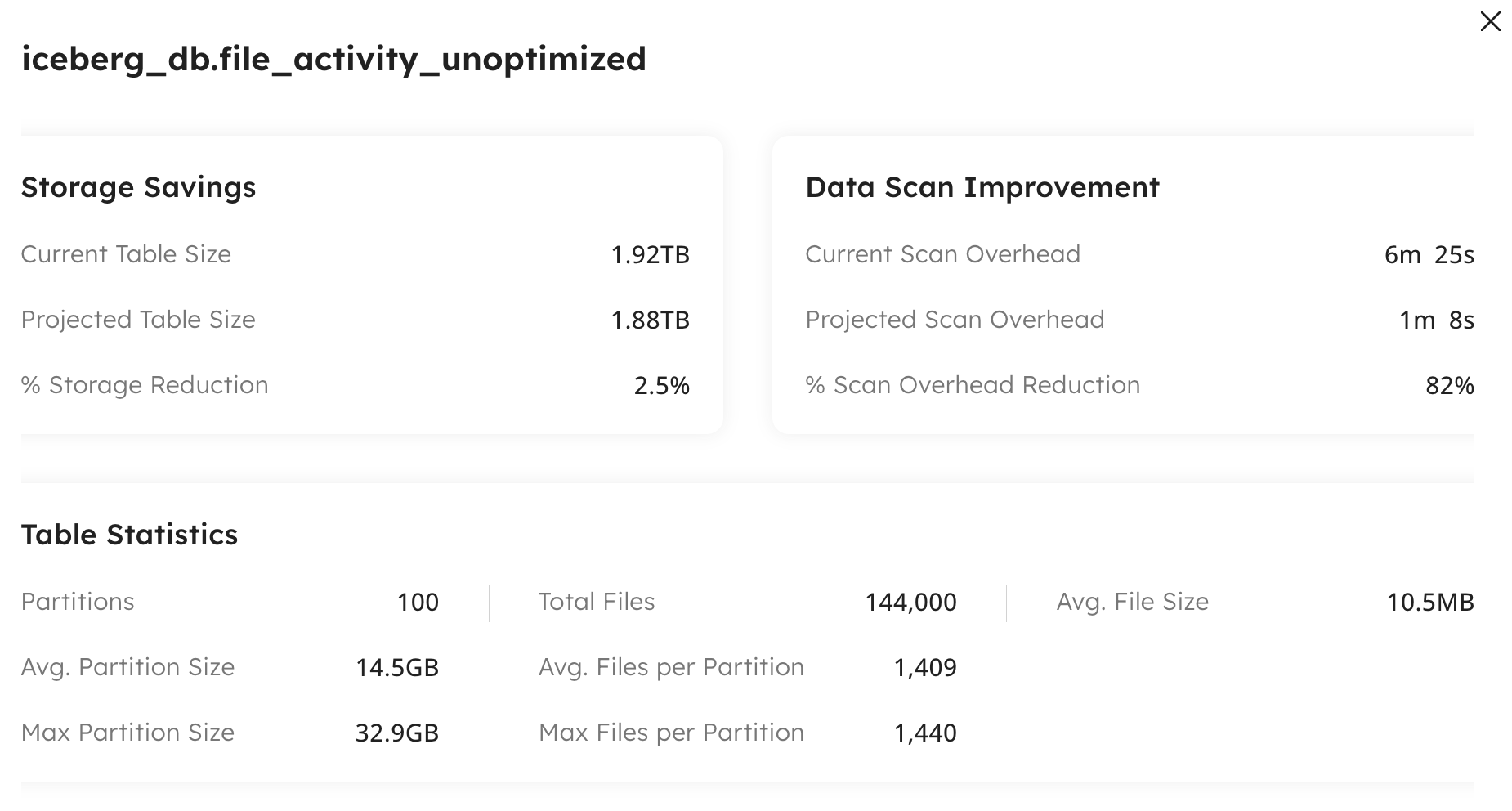
Identify waste in your existing Iceberg lakehouse and get an immediate performance boost.

Or, build your first Iceberg lake with Upsolver. Fully-optimized by design.
Real-time database replication
Give your business an edge with up to the minute data! Easily ingest data from operational stores to the warehouse and Apache Iceberg-based lakehouse with minimal configuration and automatic table maintenance and optimization
High-volume CDC connectors
Our source and destination connectors are built with scale in mind, offering the most reliable, fast and cost-effective replication solution for PostgreSQL, MySQL, MongoDB, SQLServer and more.
With our Apache Iceberg connector, merging updates and deletes in the data lake is easy and painless. Our table optimizer continuously monitors and adjusts your data to ensure peak query performance for analytics users.


Leave the heavy lifting to us
Declare your ingestion job and we’ll do the rest like…

Schema evolution
Automatically handle schema drift including new or removed columns, column renames and data type changes

Guaranteed delivery
Reliable, strongly ordered, exactly-once delivery at any scale

Eliminate bad data
Quality expectations allow you to alert and eliminate bad quality data from entering your warehouse or lakehouse
Decoupled architecture,
unmatched performance
The first and only decoupled state store for data movement and shared storage.
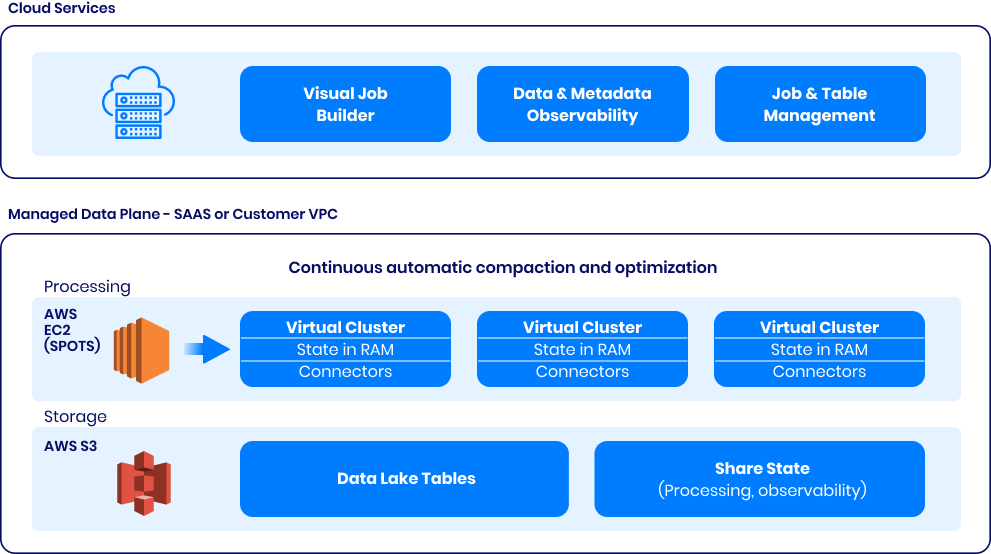
Accelerating the lakehouse layer
Across engineering and data teams

