Explore our expert-made templates & start with the right one for you.
Low Code Data Pipelines
for Cloud Data Lakes
Speeding Delivery of Analytics-Ready Data
Talk to an Expert








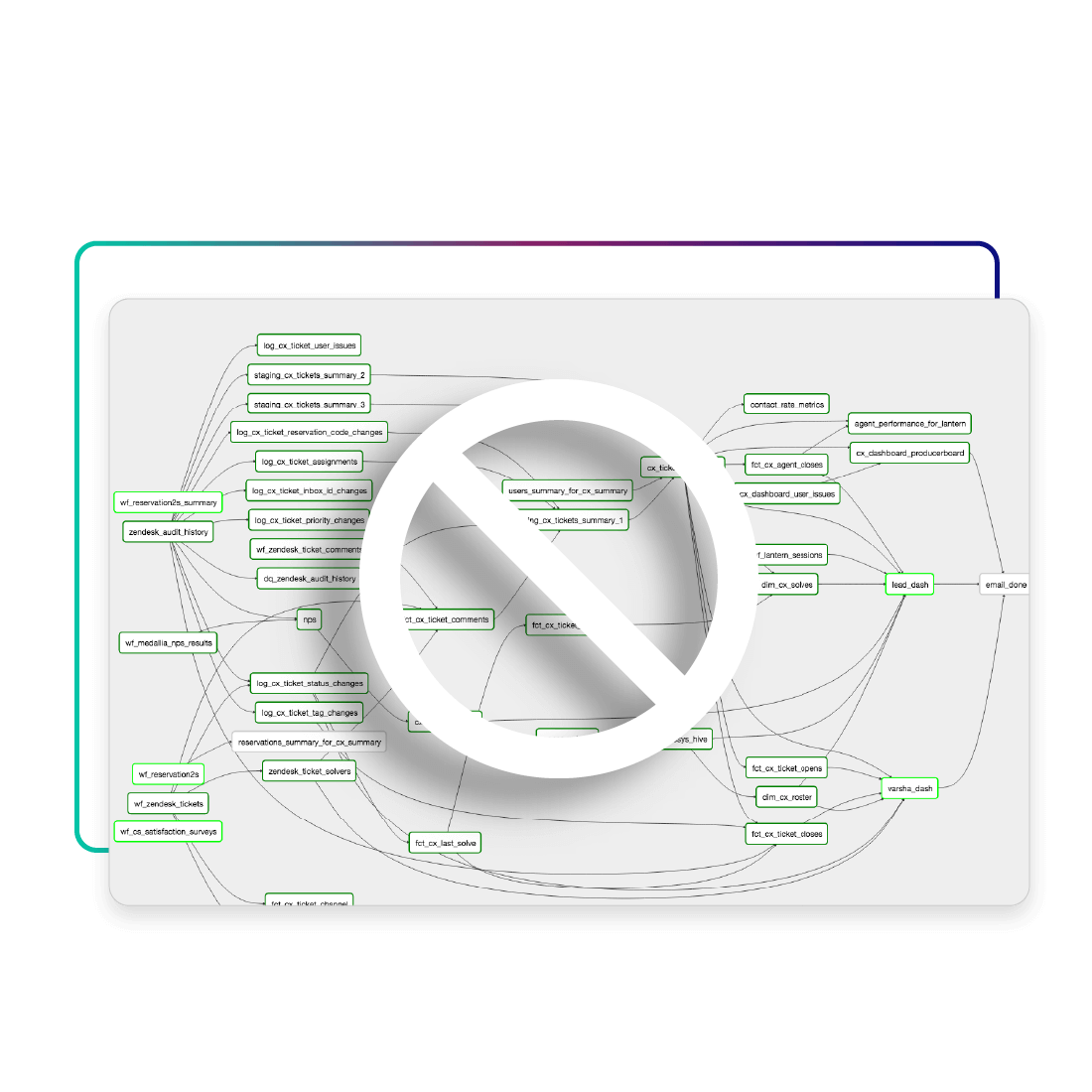
Eliminate the Complexity of Data Pipeline Engineering
- Reduce 90% of ETL and custom pipeline development
- Deliver queryable data from streaming & batch sources
- Scale pipelines from GB’s to PB’s with near-zero IT
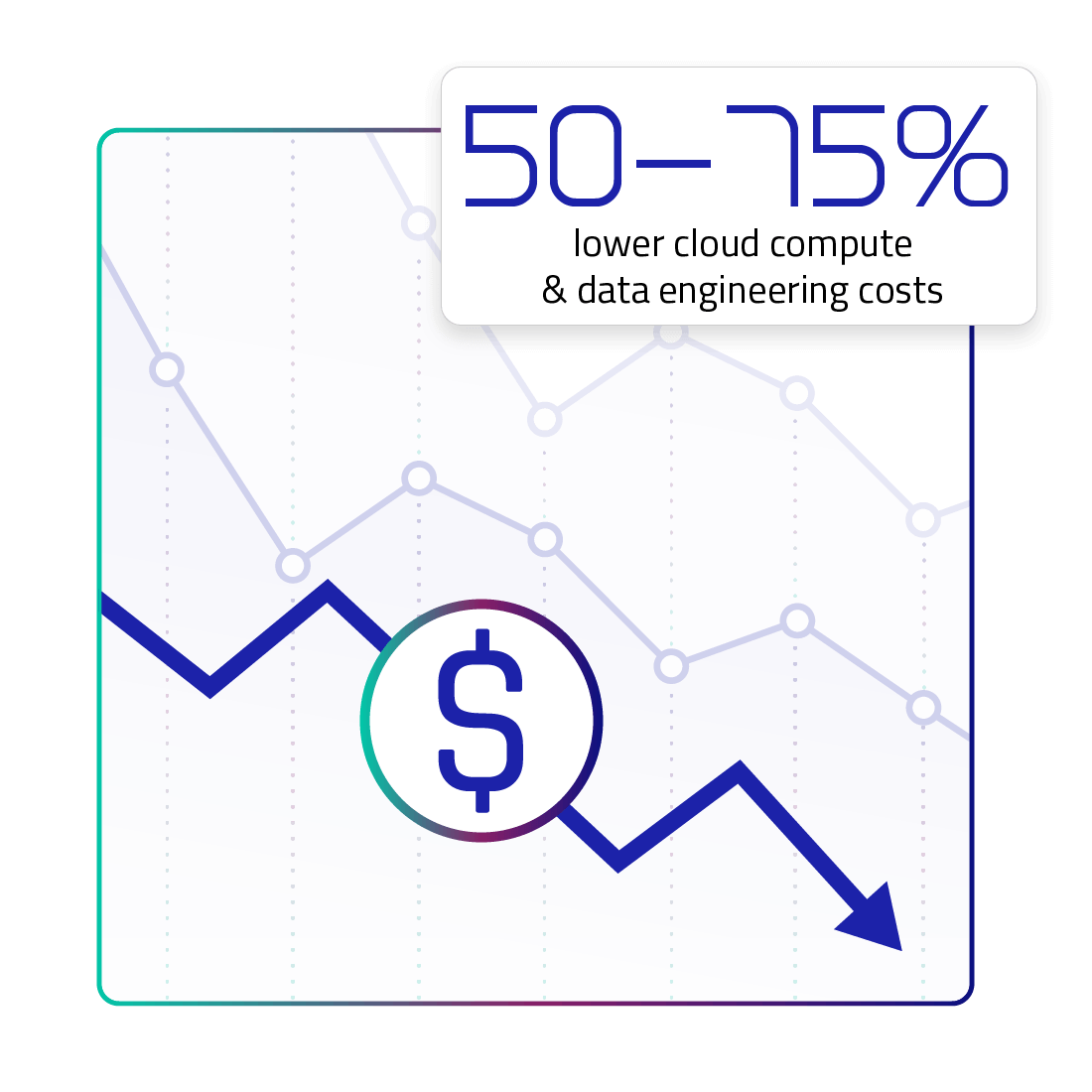
- Lower cloud compute & engineering costs by 50-75%
Build High-Performance, Declarative Data Pipelines with a Visual IDE
- Define pipelines using only SQL on auto-generated schema-on-read
- Easy visual IDE to accelerate building pipelines
- Add Upserts and Deletes to data lake tables
- Blend streaming and large-scale batch data
- Automated schema evolution and reprocessing from previous state

Automate Pipeline Orchestration and Data Lake Table Management
- Automatic orchestration of pipelines (no DAGs)
- Fully-managed execution at scale
- Strong consistency guarantee over object storage
- Near-zero maintenance overhead for analytics-ready data
- Built-in hygiene for data lake tables including columnar formats, partitioning, compaction and vacuuming
High Performance at Scale on Complex Data
- 100,000 events per second (billions daily) at low cost
- Continuous lock-free compaction to avoid “small files” problem
- Parquet-based tables for fast queries
- Enables low-latency dimension tables using streaming upserts

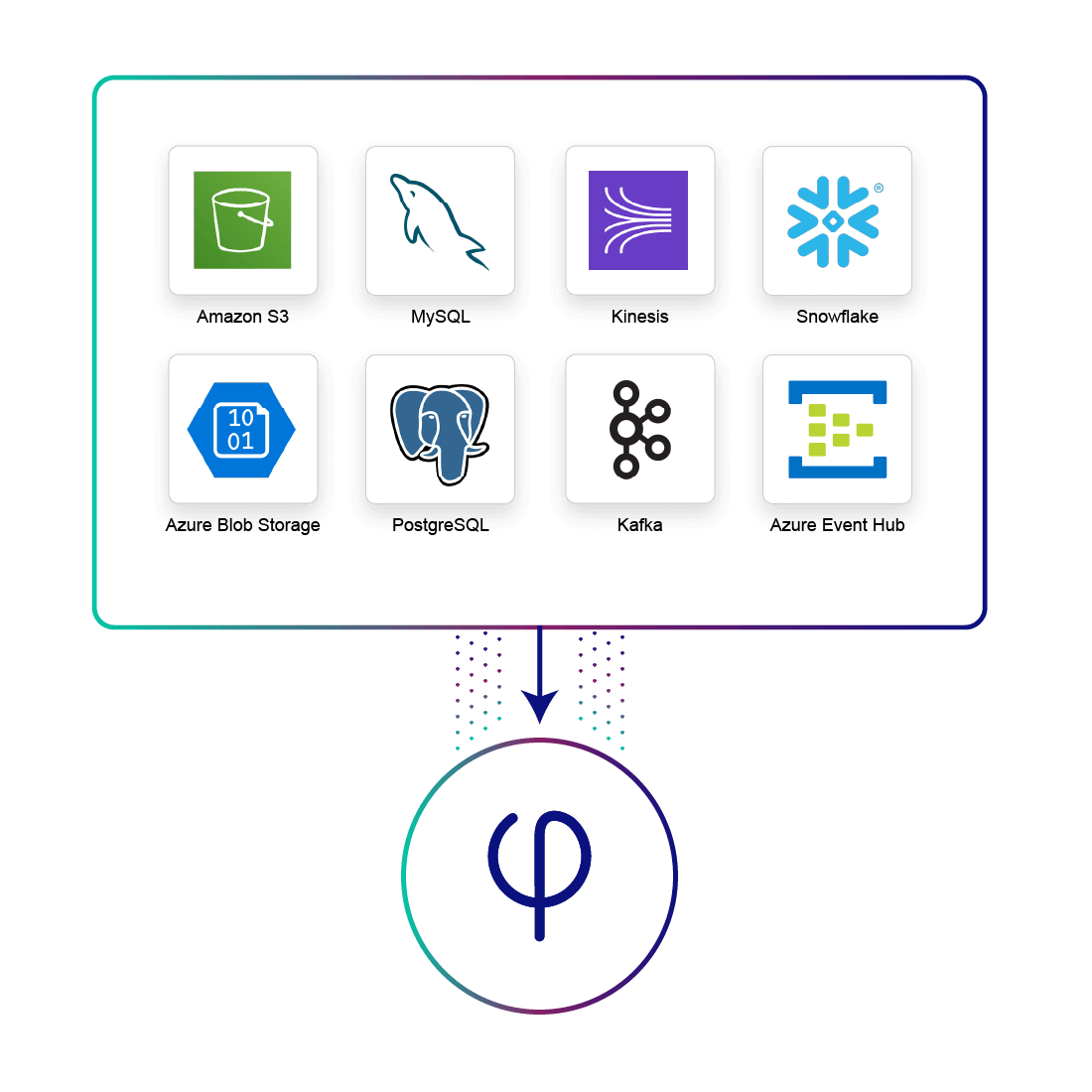
UI-Driven Ingestion from Streams, Files, Databases
- Automatic schema-on-read and data profiling
- Data lineage visibility from source to lake to target
- Streaming data from Kafka, Amazon Kinesis and Azure Event Hub
- Transactional data from databases using JDBC or CDC
- Logs and files from cloud object storage such as Amazon S3, Google Cloud Storage or Azure Data Lake Storage
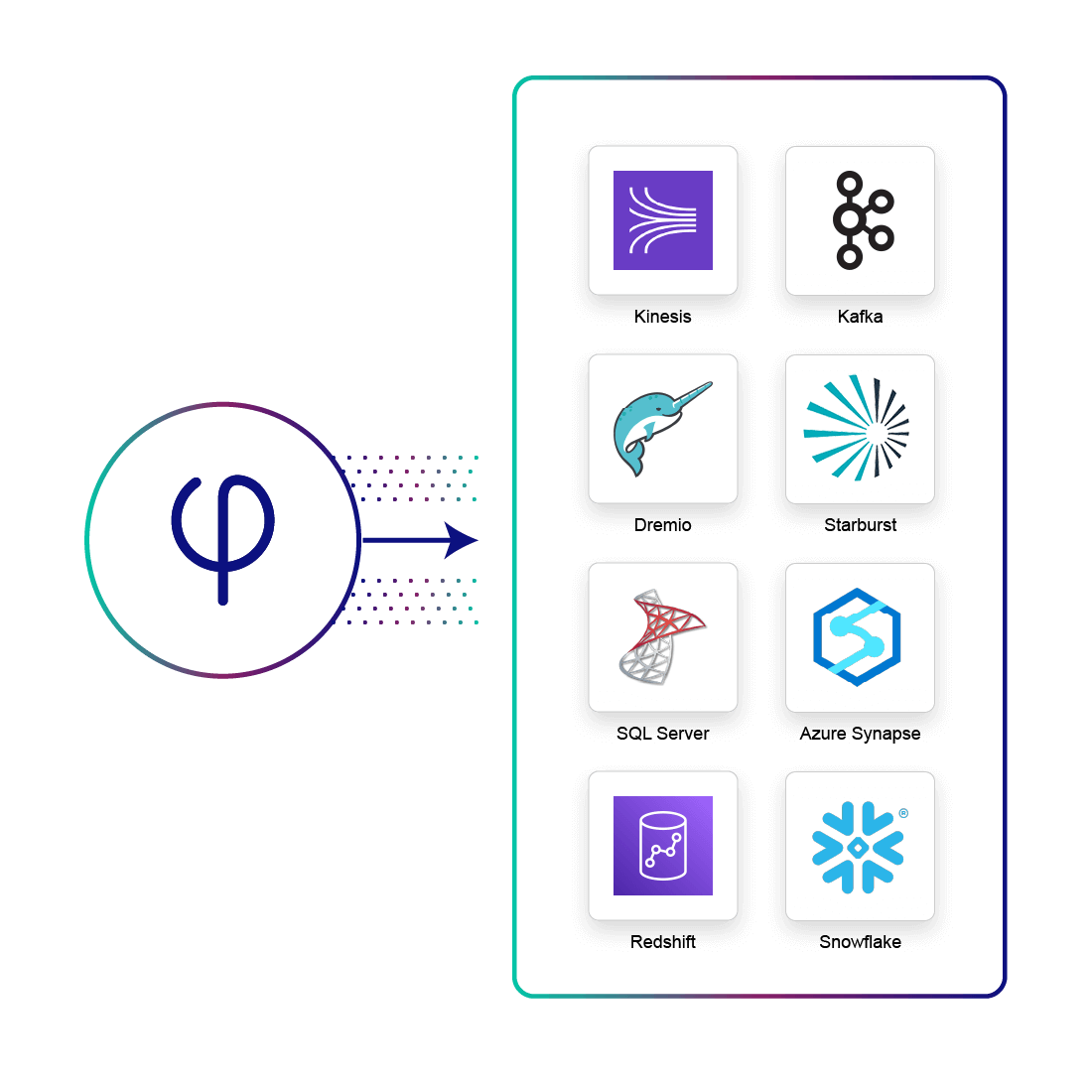
Continuously Serve Data to Lakes, Warehouses, Databases and Streaming Systems
- Integration with lake query engines: Amazon Athena, Redshift Spectrum, Dremio, Starburst, Presto, Trino & more
- Cloud data platforms including Redshift, Snowflake and Synapse
- Databases such as ElasticSearch, MySQL and PostgresDB
- Write to Amazon S3, Google Cloud, Azure Data Lake Storage
- Stream processing engines: Amazon Kinesis, Kafka, Azure Event Hub
50-75% Lower Cloud Compute and Data Engineering Costs
- Automated use of low cost Spot instances
- Automated use of low cost cloud object storage
- Continuous, high-integrity table management
- Automated vacuum of stale and intermediate data
Explore Upsolver your Way
Community Edition
Upsolver is free to use for smaller workloads. Start instantly on the Community Edition with no credit card required.
Talk to a Solutions Architect
Schedule a quick, no-strings-attached chat with one of our cloud architecture gurus.
Customer Stories
See how the world’s most data-intensive companies use Upsolver to analyze petabytes of data.
Integrations and Connectors
See which data sources and outputs Upsolver supports natively.