Explore our expert-made templates & start with the right one for you.
Upsolver and Amazon Redshift
Leverage Redshift as part of your open data lake architecture

Why use Upsolver with Amazon Redshift?
Amazon Redshift is a powerful cloud data warehouse used by thousands of organizations to run analytics and BI workloads at scale. Using Upsolver, you can seamlessly use Redshift as an integral part of your data lake architecture – storing a copy of all the raw data on S3, preprocessing the data and only ingesting the data you need into Redshift.

Already using Upsolver
Reference Architecture
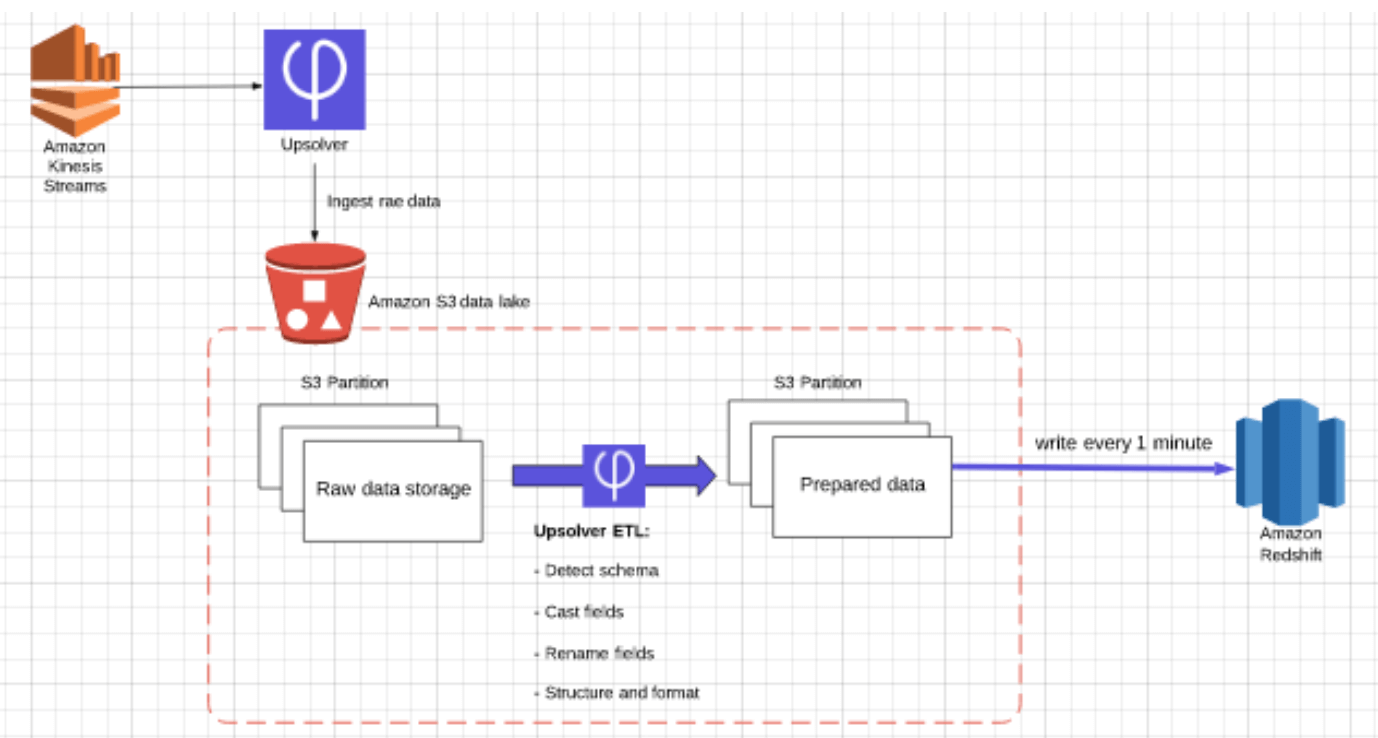
Key Features
Keep all the raw data
Leverage S3 as the raw storage layer before your data warehouse.
Use native connectors to ingest batch and streaming data into Amazon S3, then use Upsolver’s high-speed compute layer to process the data and write only the tables you need to Redshift in near real-time.
Streaming data in Redshift made easy
Stream event data, execute stateful joins and window functions.
Reduce the costs and complexity of ETLing streaming data into Redshift – Upsolver lets you run joins and aggregations directly on event streams using SQL, Python or over 200 built-in functions.
Replicate and sync your databases
Seamlessly migrate legacy workloads to Redshift.
Implement change-data-capture and upsert data into S3 and Redshift using a visual interface and skip the complexity of Delta Lake or Apache Hudi.

Start for free - No credit card required
Batch and streaming pipelines.
Accelerate data lake queries
Real-time ETL for cloud data warehouse
Build real-time data products