Explore our expert-made templates & start with the right one for you.
Cloud data integration for data-intensive companies
Upsolver is a cloud-native platform that lets you seamlessly move and transform data in an open lake architecture – providing unparalleled scalability, ease of use and cost-effectiveness.
- Managed ingestion, orchestration, object storage and transformation pipelines for batch and streaming data
- Improve query performance by delivering super-optimized data to databases or serverless query engines
- Run complex transformations using SQL – streaming joins, window aggregations, high cardinality joins
- Store all the data on S3 or Azure Data Lake to build a centralized data hub that supports any use case: log analytics, real-time analytics or change-data-capture
- Only SQL knowledge required – no coding in Spark/Hadoop
Start Your Guided Tour
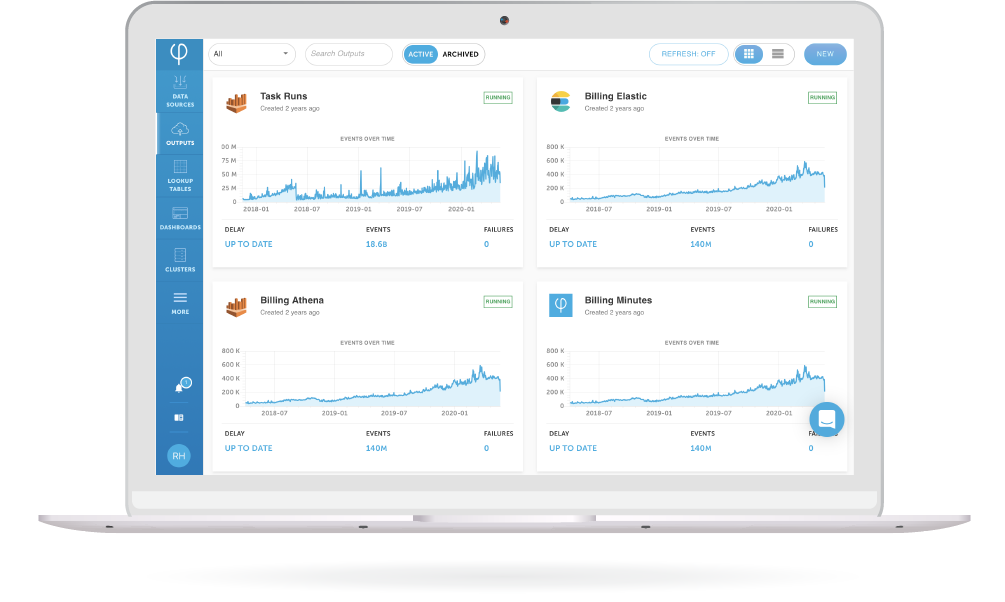
Trusted by companies that run on data
Upsolver provides the scale of big data integration tools and the ease of use of modern SQL tools
Spark Ecosystem
Databricks, EMR, open-source
- Code-intensive (Scala, Java) and difficult to manage
- Creates bottlenecks and overloads data engineers
- High infrastructure and engineering costs
Modern ELT tools
Fivetran, Matillion, DBT
- Fully managed data pipelines
- Creates vendor lock-in and overreliance on database providers
- Drives up cloud data warehouse compute costs
Upsolver
Self-service at scale
- Fully managed data hub using SQL
- Democratizes analytics for engineering and BI teams
- Scalable low-cost architecture leveraging cloud object storage
- No vendor lock-in
- Highly efficient compute engine drives EC2 efficiency
Reduce data warehouse costs with a modern lakehouse architecture
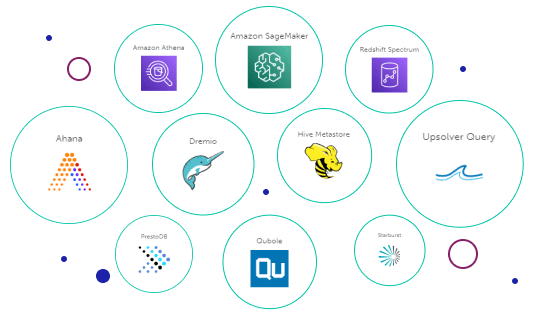
Store all your data in open file formats and deliver analytics-ready data to query engines or data warehouses
The days of monolithic enterprise data warehouses are over – today’s organization relies on a multitude of tools for storage, compute, ad-hoc analytics and machine learning. Upsolver embraces the modern data stack and lets you work with data your way – no vendor lock-in, no proprietary file formats, and no complex architecture to manage.
Technology that's built to solve your toughest data engineering challenges
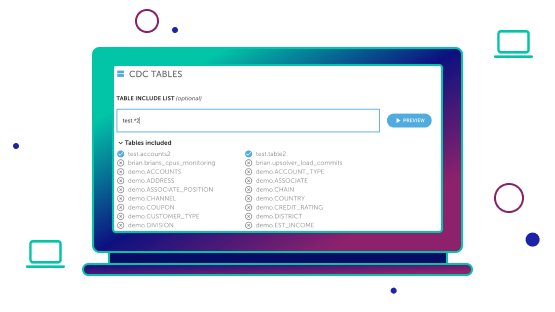
From streaming joins to change-data-capture, Upsolver was built from the ground up to simplify complex analytics projects
Upsolver runs on homegrown technology that allows us to store 10x the amount of data in-memory – unlocking powerful capabilities for streaming analytics, change-data-capture, and data lake optimization. We did the heavy lifting – all you need to do is write SQL.
Simplify Pipelines for Complex Data
- Reduce 90% of ETL pipeline development
- Deliver queryable data from streaming & batch
- Easily scale pipelines from GBs to PBs
- Eliminate 50-75% of compute & engineering costs

Start for free - No credit card required
Batch and streaming pipelines.
Accelerate data lake queries
Real-time ETL for cloud data warehouse
Build real-time data products