Explore our expert-made templates & start with the right one for you.
How Can We Help You?
Frequently Asked Questions
Commercial and Pricing
Features and Functionality
Upsolver on AWS
Under the Hood
Privacy and Security
Commercial and Pricing
Is it possible to add Upsolver to AWS billing?
Yes – when you’re buying Upsolver from the AWS marketplace, you’re actually adding Upsolver to your AWS bill. Through the marketplace you can choose to purchase Upsolver units on-demand and pay on a monthly basis or yearly basis. We also offer reduced pricing for annual contracts, which you can also purchase through the marketplace after contacting us, and this will also be charged as part of your AWS bill.
How is Upsolver priced?
Upsolver a compute-based model where pricing is based on Upsolver’s usage of EC2 servers. To reduce costs, Upsolver uses EC2 spot instances under the hood. You pay for the price of the spot instance with additional markup for Upsolver’s software, but you only pay for actual data being processed by Upsolver. To request a personalized live quote, visit our pricing page.
How is it possible to try Upsolver?
You can start a free trial of Upsolver, either on upsolver.com or through the AWS marketplace. The free trial lasts 14 days and includes extensive support from the Upsolver teach team, including both hands-on training as well as technical consultation: we help you define the use cases and how it’s best to implement them, and we make sure that you’re getting something that works on a production scale before you decide to spend a single dollar.
What is Upsolver's support model?
For ongoing support we are available via In-app chat, Slack and video calls as needed. We also provide 24X7 phone response for critical issues, based on agreed-upon metrics which we continually monitor.
Features and Functionality
Does Upsolver support databases as input sources?
Upsolver supports additional input databases using Amazon’s Data Migration Service (DMS). Upsolver can read the inputs generated by DMS, write them to S3 and create corresponding tables in Athena or use them for other ETL pipelines. Upsolver can support any of the databases supported by DMS.
How does Upsolver handle data retention?
Users can define retention policies for every object in Upsolver, whether it’s a data source or an output. Upsolver would automatically delete data after that period. Upsolver will also check to see if the files it is deleting are needed for any ETL process before doing so, which minimizes errors compared to manually deleting folders on S3.
Does Upsolver support batch loads or only streaming?
Upsolver supports batch data loads but is built on a streaming-first architecture. E.g., if you’re looking to output data once an hour and then query the aggregated data to reduce costs and latency – Upsolver can run that batch operation, but under the hood it will use stream and micro-batch processing to process every event at a time, and indexing to join with historical data.
Can Upsolver work in a hybrid on-premises and cloud environment?
Upsolver’s native connectors to Kafka and HDFS allow you to ingest data from on-premises deployments into the cloud. Currently data processing is done in the Cloud.
How does Upsolver handle missing data?
Upsolver’s S3-to-S3 architecture ensures exactly-once processing, which means there will be no duplicate or missing data.
Can Upsolver handle large volumes of messages per second?
In the Upsolver architecture, storage and compute are decoupled. Upsolver handles increases in message volume by scaling out the compute cluster. You can choose a scaling strategy to keep consistent low latency.
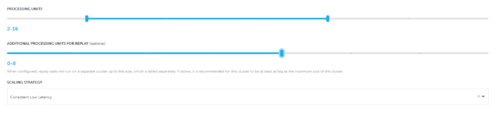
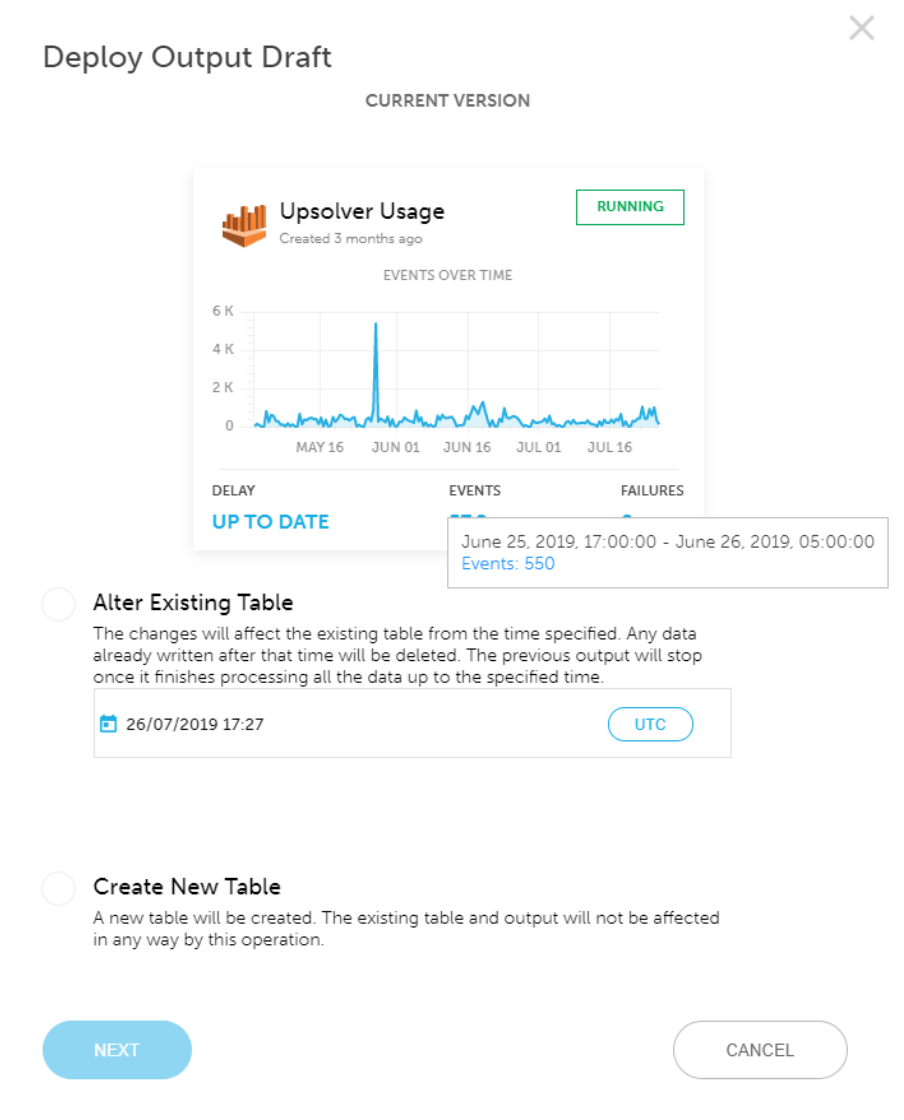
Can I edit existing tables to reflect changes in the data?
Yes, Upsolver allows you to alter existing tables in Athena, including adding new columns to a table that’s already in use. These changes will take effect both proactively and retroactively, based on the timestamp you chose.
Can I send messages from the same input to different output fields?
Yes, using the Upsolver UI you can define filters that will apply to that output, based on a field or fields from the event stream. For highly complex parsing you should use the Upsolver API.
Does creating different outputs from the same input require reading data source (e.g. Amazon Kinesis) multiple times?
You will only read the source a single time. Data is written to S3 and then distributed to multiple outputs. We do this because keeping a copy of the raw data on S3 is cheaper than Kinesis/Kafka, data retention can be longer and there is no risk that one output will cause slowdowns in other outputs.
Can Upsolver be used with Snowflake?
Yes. For Snowflake, Upsolver will store the data on Amazon S3 and Snowflake will read from there.
How does the system scale?
Storage and compute are decoupled. S3 is used for storage and EC2 Spot instances are used for compute. Scaling is linear since local disks are not used at all.
How is the system managed?
Upsolver manages the cluster remotely including troubleshooting, version updates, scaling and monitoring.
How can I learn how to use Upsolver?
Our documentation and Support team are always available to get you started and assist along the way. We also provide an on-demand online training course. For more information, please contact our team.
How is the Upsolver Application being updated?
Upsolver is a cloud-based SaaS. As such, the Upsolver application is updated from the cloud periodically.
The process is gradual and the service remains available during the entire update process with zero downtime.
Can I monitor Upsolver using my own monitoring system?
Yes. Upsolver’s monitoring solution enables sending pre-configured metrics to your existing monitoring system. Supported monitoring systems are Datadog, Amazon CloudWatch, InfluxDB, Elasticsearch, SignalFx and others per request.
What infrastructure does Upsolver run on ?
Upsolver runs in the cloud. We currently support Amazon Web Services and we will soon add support for Microsoft Azure.
Can Upsolver be used in an event-based use case ?
Yes. Please contact the Upsolver Support team so we can customize a solution for this use-case for you.
From which sources can I ingest data to Upsolver?
Upsolver supports data ingestion from the following several types of sources such as databases, streaming services (such as Amazon Kinesis and Apache Kafka) and object store services (such as Amazon S3 and Google Cloud Storage).
To which targets can I send my data using Upsolver?
Upsolver supports sending your data to various types of destinations such as distributed SQL query engines (such as Amazon Athena), databases and data warehouses, streaming services (such as Amazon Kinesis and Apache Kafka), and object store services (such as Amazon S3 and Google Cloud Storage).
Does Upsolver support Upserts?
Yes. Read more about how Upserts in our documentation.
How does compaction work?
Compaction is a process in which small files are being merged into one bigger file for improved performance. Read more about this in our blog.
How does Upsolver handle failures?
Full traceability (Event Sourcing) is built into the platform. Upsolver’s architecture follows event sourcing principles and is based on an immutable log of all incoming events. These events are then processed with Upsolver ETL to create a queryable copy of the data. Unlike databases where the state constantly changes (which makes it hard to reproduce its original state without configuring, a change-log), in Upsolver you can always ‘go back in time’ and retrace your steps to learn about the exact transformation applied on your raw data, down to the event level. You can fix a bug in your ETL and then run it using the immutable copy of your raw data.
Can Upsolver be used in a timer-based use case ?
Yes. Please contact the Upsolver Support team so we can customize a solution for this use-case for you.
Upsolver on AWS
Can you use Upsolver to join multiple Kinesis streams?
Yes! Each Kinesis Stream will be a data source in Upsolver, and you can join any two data sources together: Kinesis-Kafka, Kinesis-Kinesis, Kinesis-S3, S3-S3. Any combination would work out of the box.
How do I select which metadata and model to query on S3?
With Upsolver, this would be done using SQL, When you write you’re query, you define the schema that you’re going to create in Athena. This can also be done via the visual UI which allows you to select fields within your data sources to populate Athena tables.
Does Upsolver store the original JSON messages on S3?
The historical JSON files are batched together and kept in compressed Avro for higher performance and lower cost of storage. Access to historical data is available via the Replay feature.
Can Upsolver work with Redshift Spectrum or Presto over EMR?
Yes. Upsolver stores all metadata in the Glue Data Catalog, so that once you’ve created a table in Athena, it can also be immediately accessed in Redshift Spectrum or Presto over EMR, which also read metadata from Glue.
How quickly will my streaming data be available in Athena?
Using Upsolver, your data should be available in Upsolver within 5 minutes of appearing in Kafka, and often in 2-3 minutes.
How does Upsolver output data to Athena?
Upsolver offers unique end-to-end integration with Amazon Athena. Tables are created via Glue Data Catalog, to which Upsolver will add:
- Optimization of S3 storage for performance. See this blog post for the details.
- Make data available in Athena in near real-time to Athena.
- Ability to define updatable tables in Athena(for CDC).
- Option to edit tables.
- Historical replay / time-travel.
How do you ensure that Athena tables are efficiently queryable over time? Do you change the partition or files over time?
Upsolver continuously optimizes your S3 storage to ensure high query performance in Athena. We start with 1-minute Parquet files (for latency reasons) and compact the files into bigger files for performance. Upsolver will keep the table data consistent using the Glue Data Catalog.
Under the Hood
Does Upsolver ETL the data before or after ingesting it into the data lake?
Both! When Upsolver connects to a data sources such as Apache Kafka, it serializes all the data from Kafka into an S3 bucket; after performing transformations, every operation is written back to seperate storage on S3. By creating this architecture that leverages two layers of storage on S3, we can guarantee exactly once processing without data loss or duplication.
How does Upsolver handle data integration?
Upsolver uses its own data processing-engine coded entirely in Scala, and leveraging a fully decoupled architecture. This enables all the processing to be done on EC2 without using any local storage, and using only S3 for storage.
Where does Upsolver create and store indexes?
Upsolver’s indexes are Lookup Tables, which are also stored on Amazon S3. These indexes are loaded into memory when you’re actually running the ETL. Thanks to Upsolver’s breakthrough compression technology, you can store much larger indexes in RAM without managing NoSQL database clusters.
Privacy and Security
Does Upsolver store user data or PII?
Upsolver doesn’t store any customer data. Upsolver stores all the data it processes on an S3 bucket on the customer accounts. When Upsolver is deployed on private VPC, even Upsolver employees don’t have access to the data. The only data sent to Upsolver is billing information and monitoring information to support your deployments remotely. This means there are no issues around compliance, PCI or PII when using Upsolver.
How does Upsolver handle data privacy issues for compliance with HIPAA, GDPR, etc.?
Upsolver gives you on-premises level data privacy, in the cloud – even Upsolver employees don’t have access to the data (when in private VPC). Users can also implement masking as part of the ETL process.
What level of security does Upsolver offer?
Upsolver is as secure as your AWS account – it can be deployed in your VPC, which means that even Upsolver employees will not have access to the data. Alternately you can deploy on Upsolver’s VPC on AWS.
What kind of access control does Upsolver provide?
You can define read-only users in Upsolver, and grant/deny permissions to every object using a similar model to AWS IAM. You can also create separate workspaces to reduce complexity.

Get our technical whitepaper
Discover how Upsolver helps leading organizations manage and scale their cloud data lake infrastructure.

Why not try
a demo?
See Upsolver in action and schedule a live demo presentation to see how we can prepare and deliver data at massive scale in a matter of minutes

Begin a free trial, no strings attached
If you’re not sure about us, simply start a free trial. See how easy it can be to manage your data lake and prepare data streams for analysis with a free, fully-featured trial of Upsolver.
Visit our big
data blog
Keep up with data trends and learn more about the big data landscape through our Upstream blog.