
Explore our expert-made templates & start with the right one for you.
Upsolver October 2023 Feature Summary
-
 Rachel Horder
Rachel Horder
- Release Notes
- October 27, 2023
Welcome to the October 2023 update. This month brings major improvements, enhancements, and optimizations to the Upsolver UI, making ingesting your data even easier. Read on to discover what we’ve been working on.
This update covers the following releases:
Contents
- UI
- Jobs
- CDC Jobs
- SQL Queries
- Enhancements
UI
New and Improved Look and Feel
Our mission here at Upsolver is to make big data ingestion really easy. Our engineers have been working super hard this last month to further improve the Upsolver UI, ensuring you move your data from source to target with the least amount of friction. The biggest change you’ll notice when you next login to your account is the new-look Wizard. Let’s dive in and see how this will have your jobs up and running in minutes!
Start by selecting your source – we support the major streaming, file, and database sources – and then select your target. If you don’t see your source or target in the list, please drop us a line, we’re continually adding more data platforms. When you’ve selected your options, click Next.
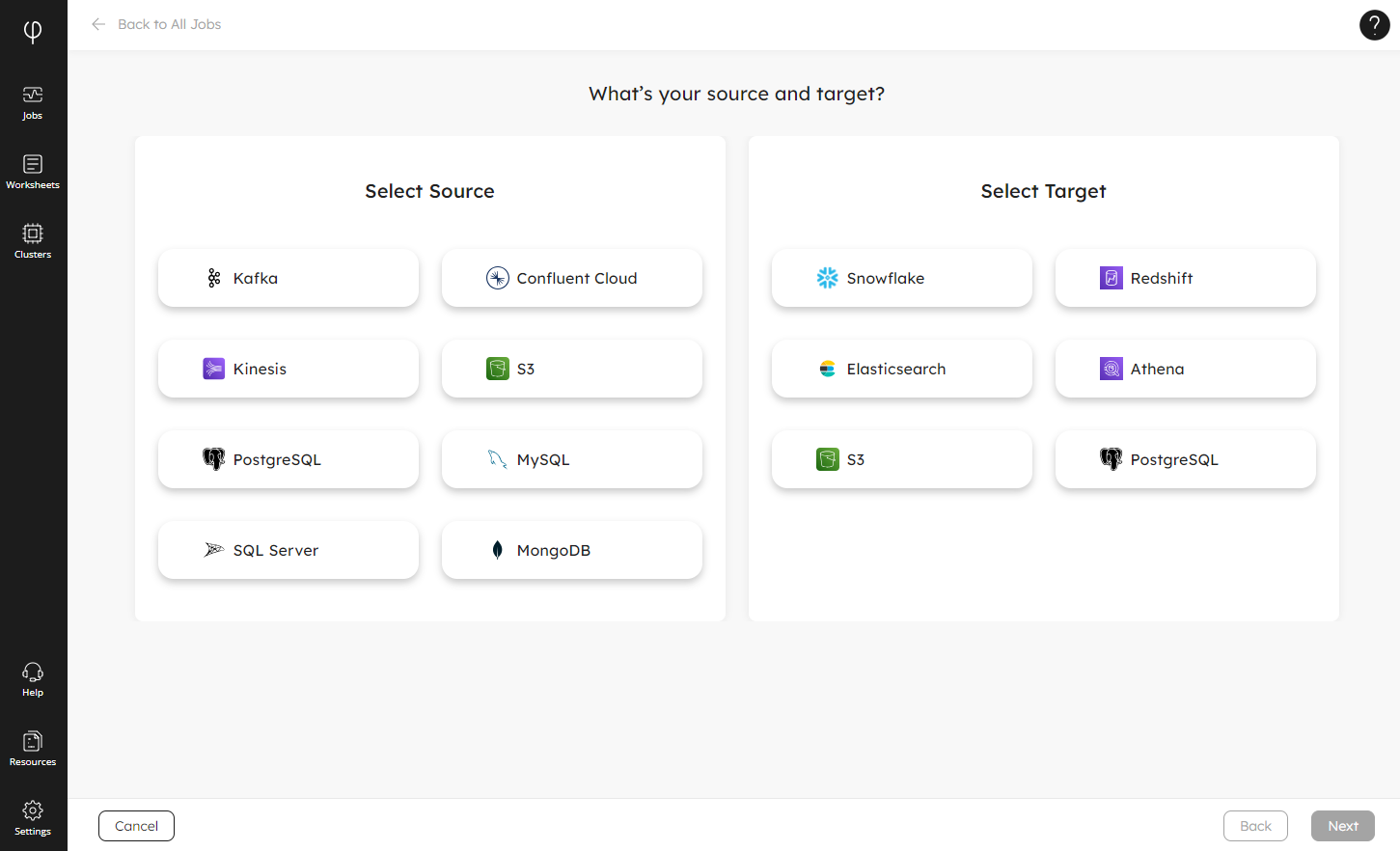
Depending on the source and target combination you select, the Wizard will either present you with a SQL template to help you create your connections and build your first pipeline, or it will guide you through these steps using the UI.
For example, if you choose Microsoft SQL Server as your source, and Amazon Redshift as your target, the Wizard provides the following template:
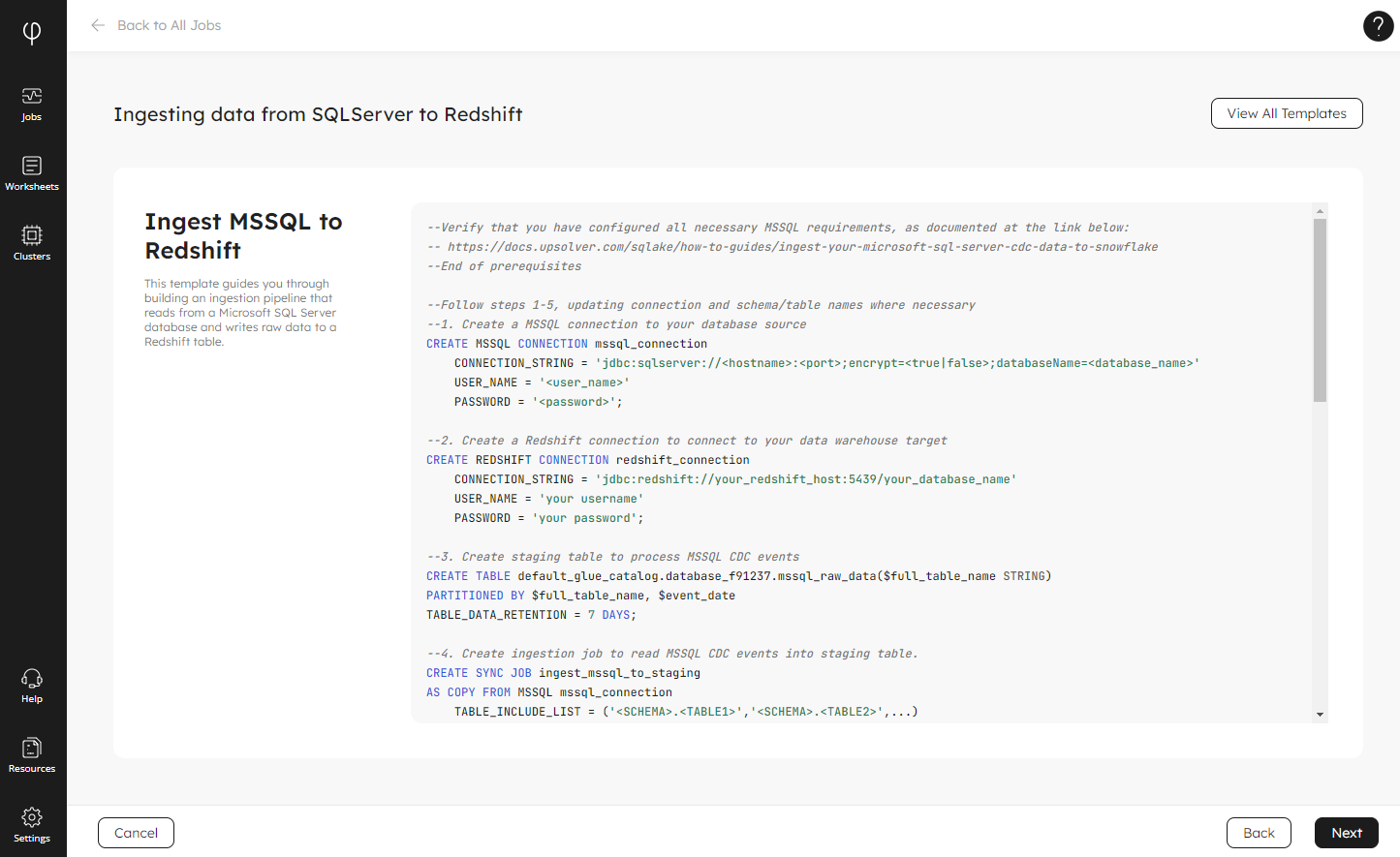
Click Next, and the template automatically opens in the Upsolver query editor, ready for you to work on:
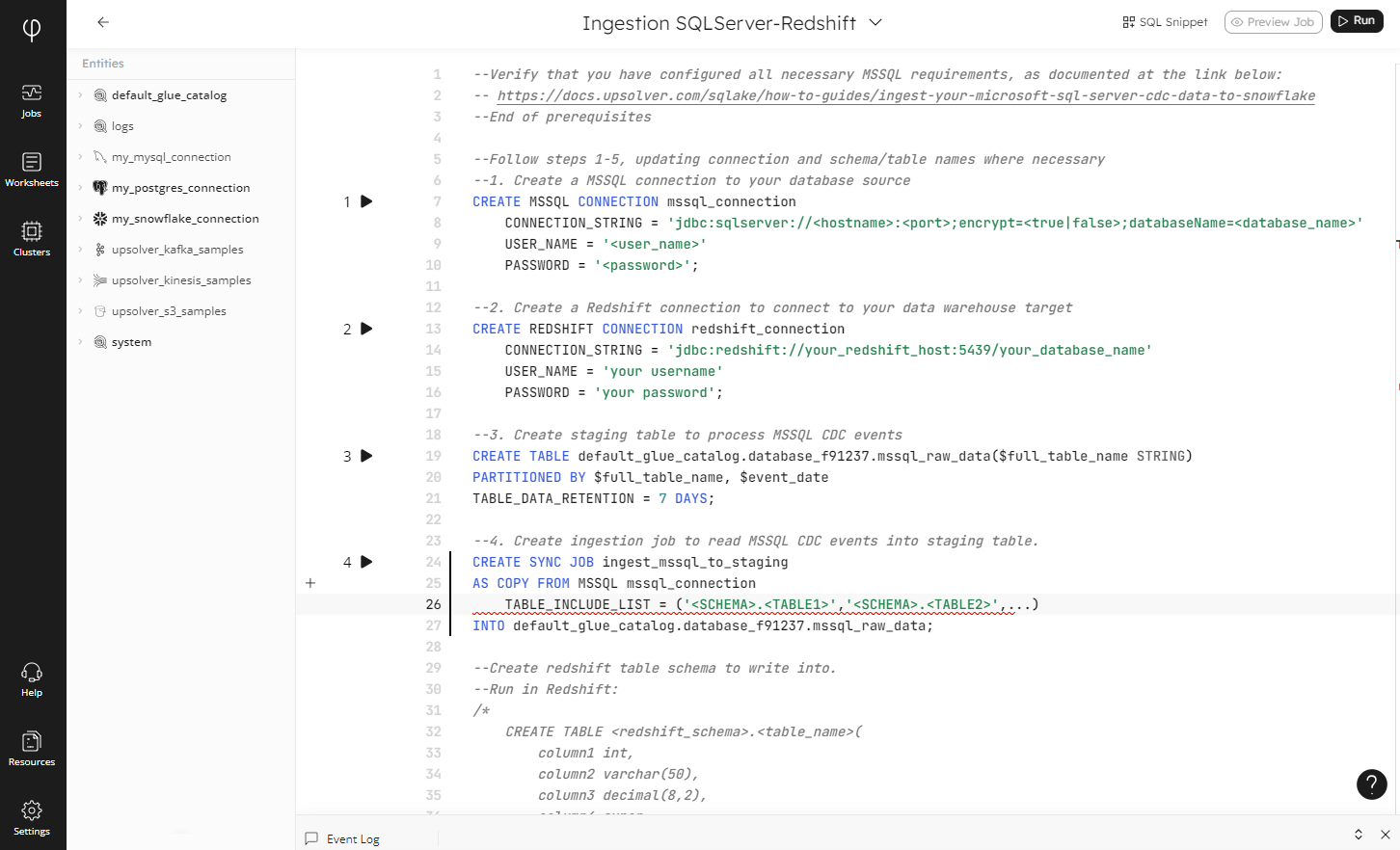
Each template is annotated with instructions at each step, with basic code to get you started. Our documentation provides plenty of support to help you create connections and build both basic and advanced jobs.
If you choose Snowflake as your target, the Wizard takes you end-to-end, and you can create your job without writing a single line of code!
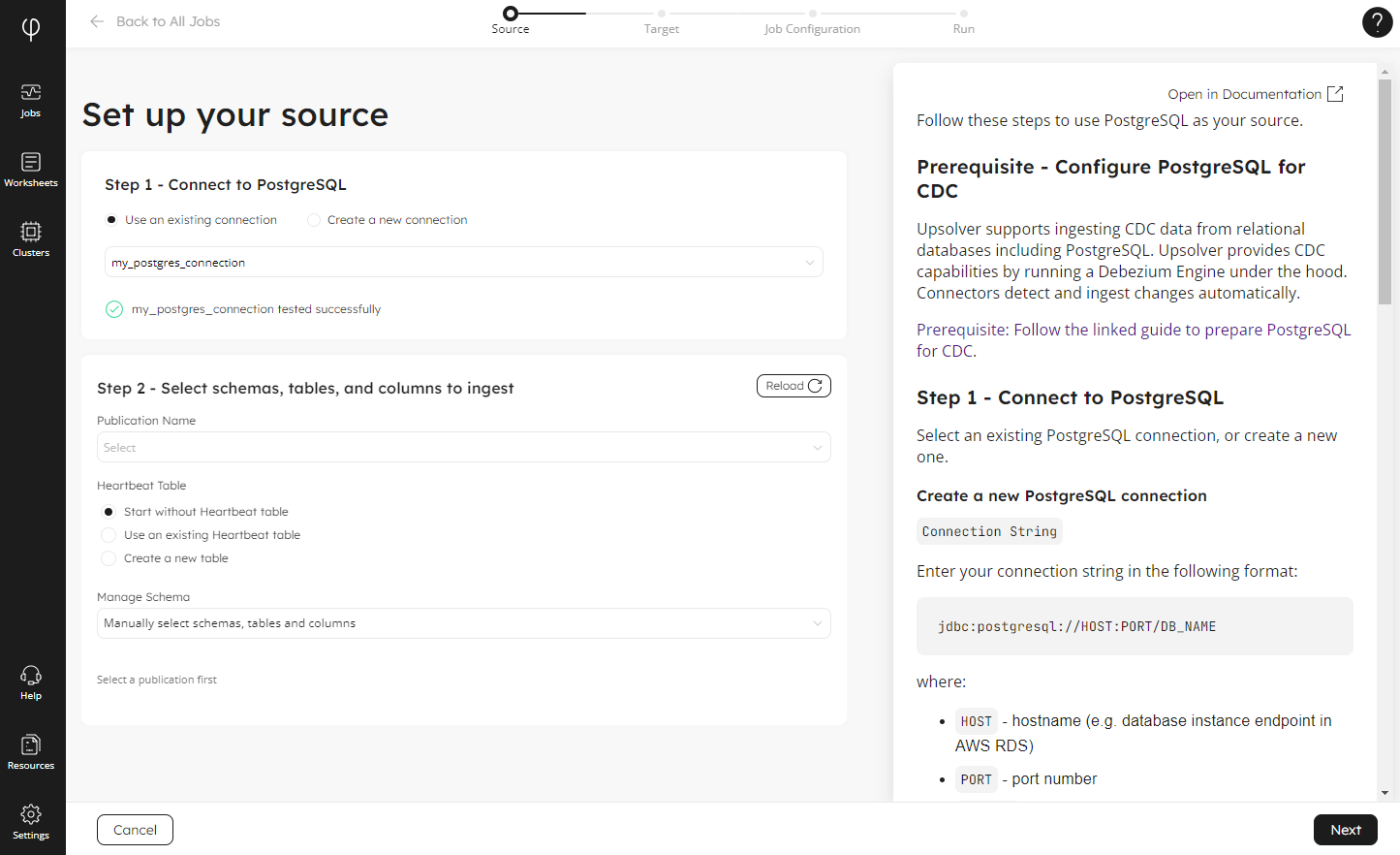
First, the Wizard walks you through the process of creating your connection and configuring your source (you will be presented with an adapted version of this page for other sources, such as MongoDB or Amazon S3 for example, as all have slightly different configurations).
In the example below, using PostgreSQL as the source, you create a new, or use an existing, connection. Then you choose the publication name, configure the heartbeat table, and select which schemas to ingest.
Next, the Wizard enables you to create or use an existing connection to Snowflake and select your target schema:
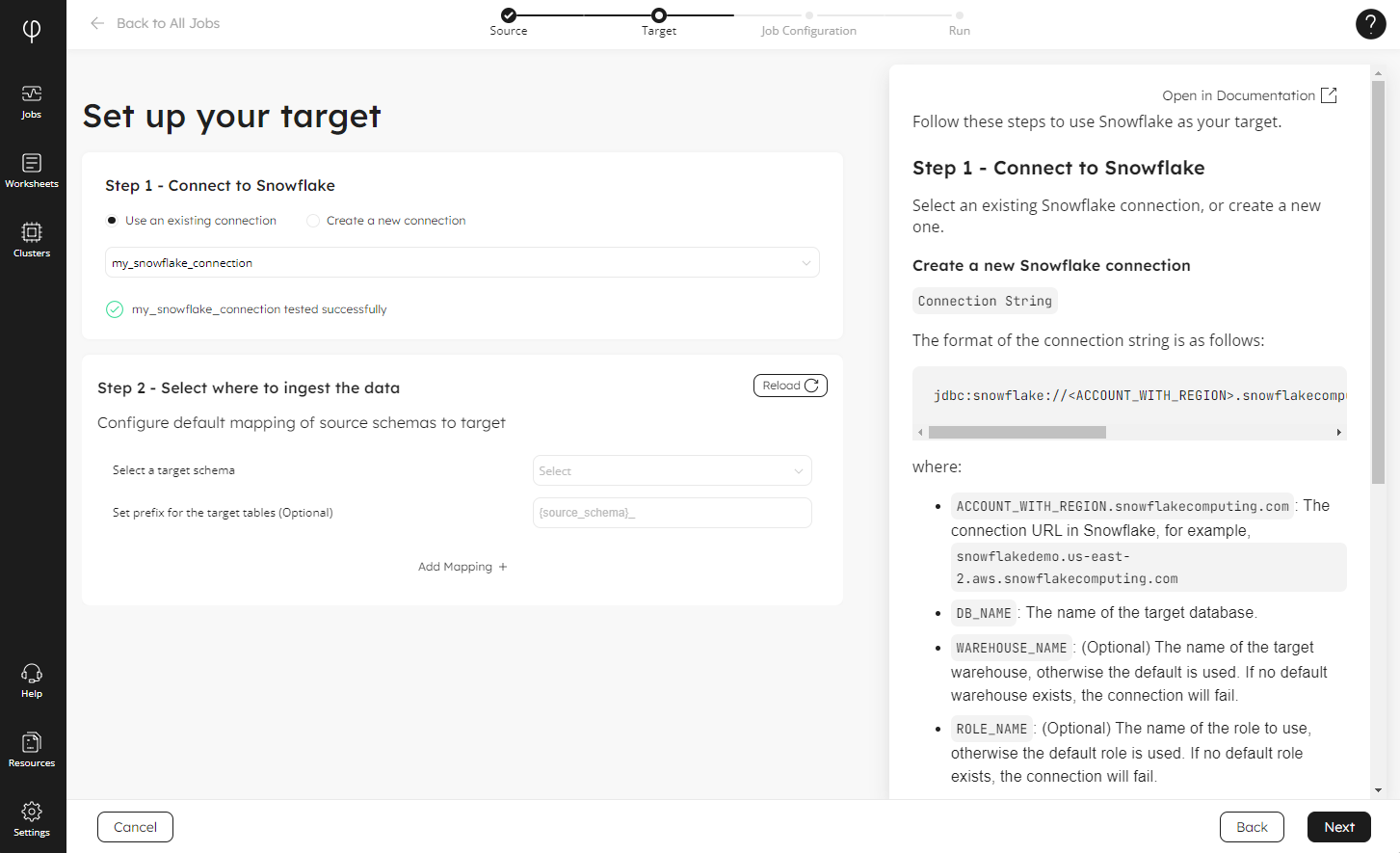
You can then configure the options to name your job, set how often you want Snowflake to be updated, and how you want to handle deletes:
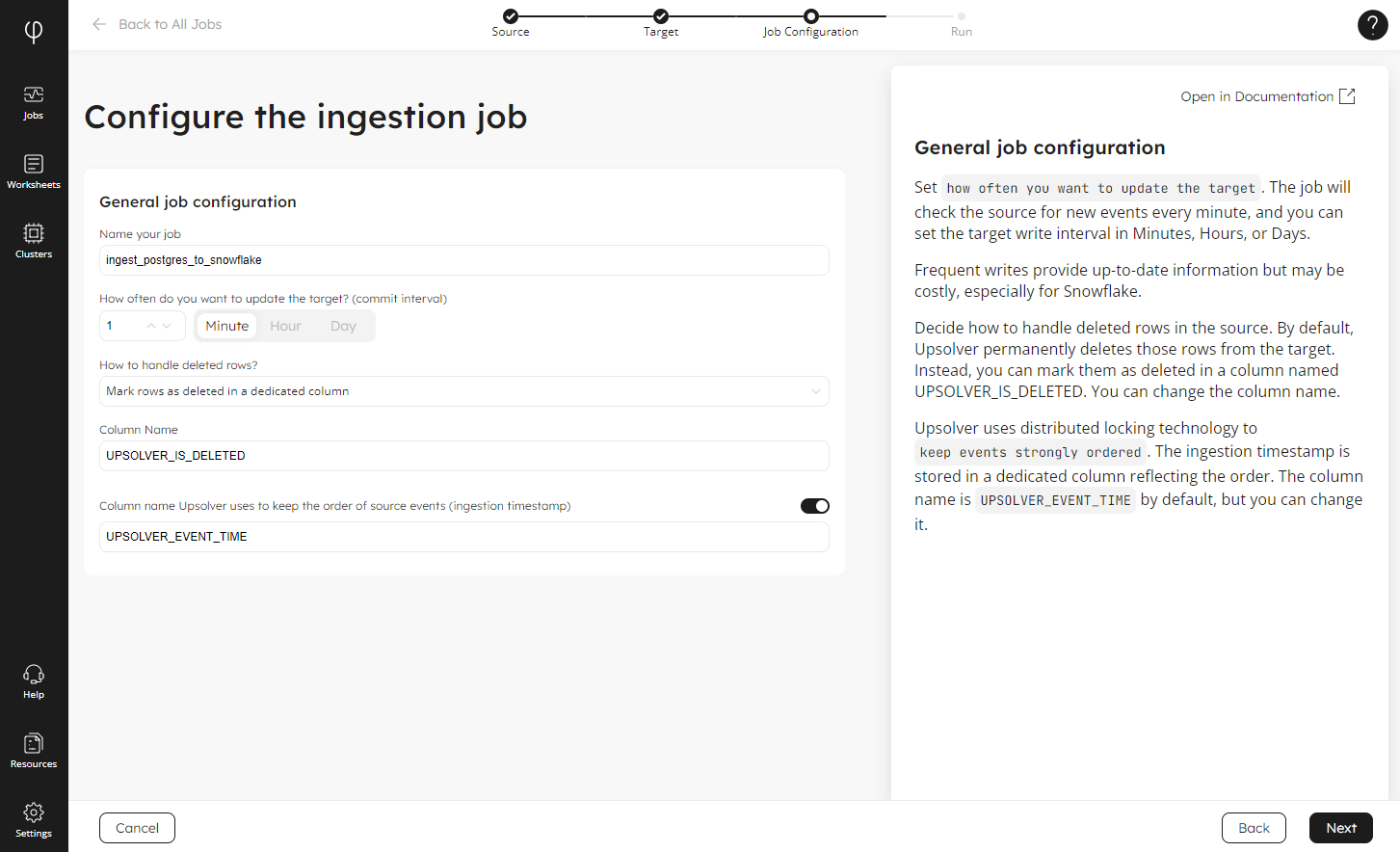
The next screen presents you with the SQL code to create the job based on your choices:
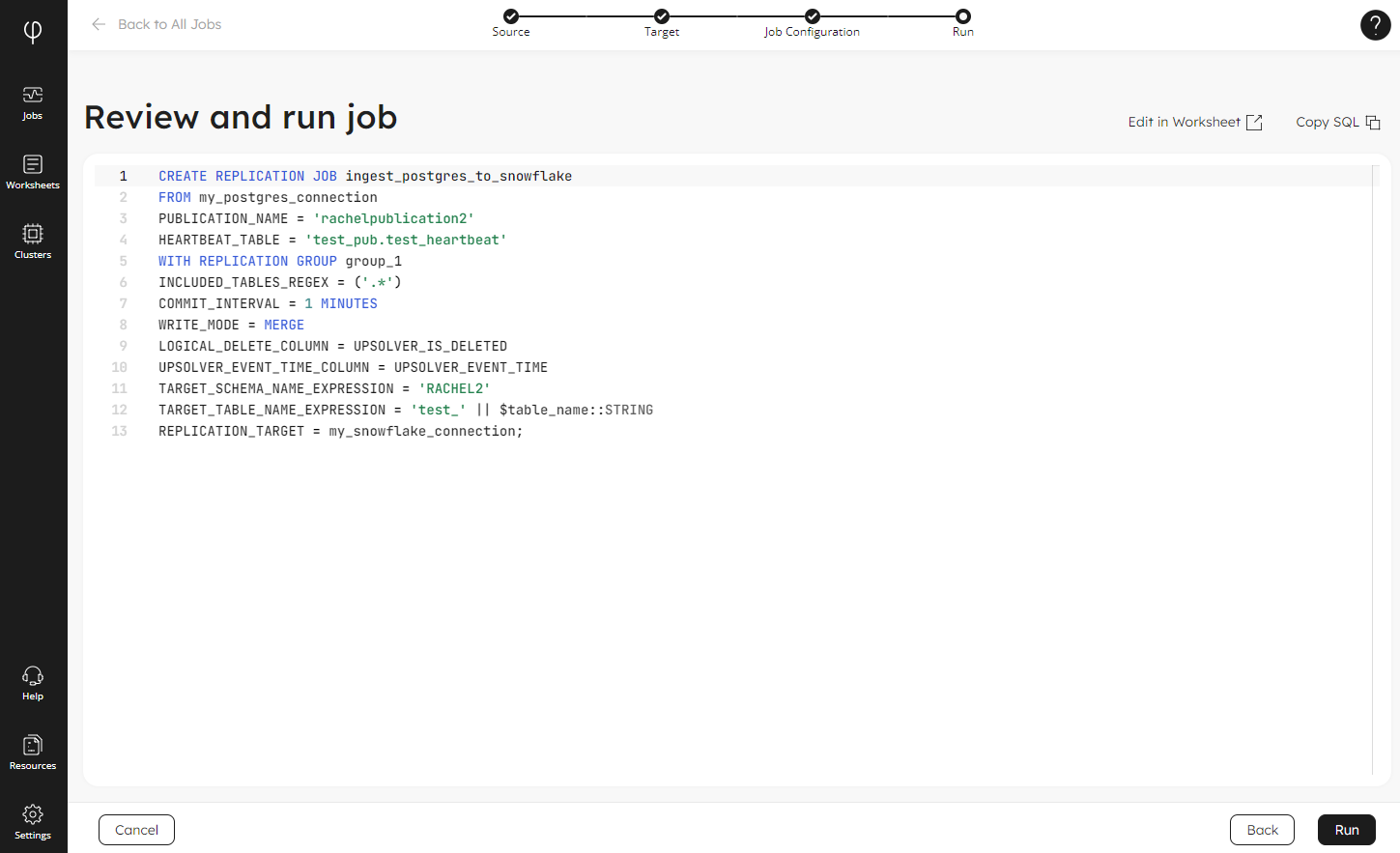
The Wizard provides this basic job template, which is adequate for many circumstances, or ready to adapt. What’s really cool about this is that you can skip this altogether and click Run to create the job without touching any code!
Alternatively, open the script in a worksheet and enhance it with expectations, exclude columns, or perform essential transformations such as masking PII data. Furthermore, if you add the script to version control, you can store a history of all the changes.
All in all, the new Wizard will help you ingest your data with ease!
Jobs
Treat Names as Globs in Apache Kafka Jobs
A glob is a string of literal and/or wildcard characters that is used to match names. We now treat names as globs when copying data from your Apache Kafka topics. This means that stars will match any number of characters, and a question mark will match one character.
Write Dates as ISO-8601 Strings in Elasticsearch Jobs
Ask any developer what’s the biggest headache in their data world, and the chances are it won’t be anything as complex as you imagine, but something as simple as handling dates and times. If you’re ingesting data to Elasticsearch, then this is one headache we can take away from you.
Currently, any timestamp fields ingested to Elasticsearch without timezone information will be stored in UTC format, which may not be your intended outcome if the value is a local time. Thanks to our recent update, your date and timestamp types will now be written as ISO-8601 strings in jobs that write to Elasticsearch. Geek out over this extensive information on the Wikipedia site to learn more about ISO-8601.
Create Missing Table in Snowflake
We’ve added a new job option for writing data to Snowflake. If you include the CREATE_TABLE_IF_MISSING option in your job, Upsolver will create it automatically. Otherwise if you exclude this option (or set it to FALSE), the table must be created in Snowflake prior to running your job.
CREATE SYNC JOB ingest_orders_to_snowflake
CREATE_TABLE_IF_MISSING = TRUE
START_FROM = NOW
CONTENT_TYPE = AUTO
COMMIT_INTERVAL = 1 MINUTES
EVENT_TIME_COLUMN = UPSOLVER_EVENT_TIME
ADD_MISSING_COLUMNS = TRUE
AS COPY FROM kinesis_samples
STREAM = 'orders'
INTO my_snowflake_connection.DEMO.ORDERS;Check out our documentation for full details of the Snowflake job options.
Bug Fixes
We fixed a bug in synchronized transformation jobs whereby a job with a smaller write interval than another job would not read the respective data.
CDC Jobs
Exclude Tables Not in a PostgreSQL Publication
When you create an ingestion job on a change data capture database, Upsolver takes an initial snapshot of the database, using Debezium to handle the snapshot and ongoing stream of events.
When Debezium first connects to your database, it determines which tables to capture. By default, all non-system table schemas are captured. By capturing the full database schema, it makes it easier to add event data for tables not yet enabled for CDC at a later date.
For example, if you have 50 tables in your database, but only 35 are enabled for CDC, the Debezium engine would by default take a schema snapshot of all 50 tables, but only capture event data for the 35 CDC-enabled tables.
We have added a new feature whereby tables that aren’t included in a PostgreSQL publication will not be part of the snapshot. So going back to our example, Upsolver now defaults to capturing only the 35 tables you enabled, leading to better performance during the snapshot process.
For Microsoft SQL Server and MySQL, adding the TABLE_INCLUDE_LIST source option to your job will perform the same action, though you will need to specify each table for inclusion. For MongoDB jobs, use the COLLECTION_INCLUDE_LIST source option. You can read more about how Upsolver works with snapshots in our documentation.
SQL Queries
Support IF EXISTS in DROP Statements
When it comes to coding, it’s always good practice to catch an error and handle it gracefully, rather than be confronted with a big red cross. That’s why our engineers have added support for adding IF EXISTS to your drop statements. If you run the following statement:
DROP TABLE IF EXISTS "my_table";And if the table does not exist, you’ll be presented with a message to say the entity does not exist, rather than an error message. A much nicer coding experience! Supported objects include: clusters, connections, tables, jobs, and materialized views.
Enhancements
Create Query Cluster
A cluster hosts a materialized view in memory for millisecond response times, and we’ve added a new feature to enable you to create a query cluster for querying your materialized views in real time.
You create a query cluster in exactly the same the way as any other compute cluster, and then attach it to your materialized view:
CREATE QUERY CLUSTER my_query_cluster
MIN_INSTANCES = 1
MAX_INSTANCES = 8
COMMENT = 'Query cluster for store orders';
CREATE SYNC MATERIALIZED VIEW default_glue_catalog.upsolver_demo.mv_physical_store_orders AS
SELECT orderid,
LAST(saleinfo.source) as source,
LAST(saleinfo.store.location.country) as country,
LAST(saleinfo.store.location.name) as name,
LAST(saleinfo.store.servicedby.employeeid) as employeeid,
LAST(saleinfo.store.servicedby.firstname) as firstname,
LAST(saleinfo.store.servicedby.lastname) as lastname
FROM default_glue_catalog.upsolver_demo.sales_info_raw_data
GROUP BY orderid
QUERY_CLUSTER = "my_query_cluster";Furthermore, if you have an existing materialized view and create a new query cluster, you can use an ALTER statement to attach it:
ALTER MATERIALIZED VIEW default_glue_catalog.upsolver_demo.mv_physical_store_orders
SET QUERY_CLUSTER = "my_query_cluster";
For more information, see CREATE QUERY CLUSTER and CREATE MATERIALIZED VIEW.
Support for il-central-1 Region
Following the recent update from AWS, Upsolver now supports the AWS Israel (Tel Aviv) il-central-1 region; however, this region is currently only supported with private VPC deployments. This enables you to run Upsolver from the AWS data centers located within Israel.
Read more about the announcement from AWS.
Reduced Amazon S3 API Calls
Finally, and this is great news for your invoices, we have reduced the number of Amazon S3 API calls to lower your S3 costs.
That’s it for this month. As we move forward, we can anticipate more new features and enhancements that will empower us to make better data-driven decisions and truly unlock the value of our data assets. Stay tuned for more exciting developments from Upsolver in November!
If you’re new to Upsolver, why not start your free trial, or schedule a no-obligation demo with one of our in-house solutions architects who will be happy to show you around.
Published in:
Blog
,
Release Notes
