
Explore our expert-made templates & start with the right one for you.
How to Deduplicate Events in Batch and Stream Processing Using Primary Keys
-
 Mei Long
Mei Long
- Building Data Pipelines
- December 18, 2022
Data duplication can result from either human error or system complications. For example, a user might accidentally create the same account twice or submit the same request multiple times. Or source systems might generate duplicate events in the process of addressing errors or recovering from a failure. Regardless – if the data isn’t fixed, it can break data integrity and cause additional data quality issues. For example, if the same order is loaded multiple times, the downstream analytics will display an incorrect calculation of revenue. Plus, the deduplication process itself can be very expensive and time consuming.
In this article, we examine various ways data platforms address data duplication. There are pros and cons to each approach; we lay these out so you can identify the best strategy for your situation when building a cloud data architecture.
Eliminating Duplicates in the Data Warehouse
Let’s take an example where raw data is published to Apache Kafka, ingested into Amazon S3 for raw storage, and then moved to a data warehouse for processing.
Traditionally, data warehouses take a three step approach to processing:
- Create a “landing zone” table with raw data ingested from S3.
- Insert distinct records into the staging table from the landing zone table.
- Truncate the “landing zone” table.
Step 1: Create a “landing zone” table with raw data ingested from S3
CREATE OR REPLACE "TEST"."PUBLIC"."raw_source"( SRC VARIANT ); COPY INTO "TEST"."PUBLIC"."raw_source" FROM @"TEST"."PUBLIC"."MY_EXT_STAGE" FILE_FORMAT = ( TYPE = "JSON" )
Step 2: Insert distinct records into the staging table from the landing zone table
CREATE OR REPLACE TABLE STG_ORDERS ( CUSTOMER_ADDRESS_ADDRESS1 VARCHAR(16777216), CUSTOMER_ADDRESS_ADDRESS2 VARCHAR(16777216), CUSTOMER_ADDRESS_CITY VARCHAR(16777216), CUSTOMER_ADDRESS_COUNTRY VARCHAR(16777216), CUSTOMER_ADDRESS_POSTCODE VARCHAR(16777216), CUSTOMER_ADDRESS_STATE VARCHAR(16777216), CUSTOMER_EMAIL VARCHAR(16777216), CUSTOMER_FIRSTNAME VARCHAR(16777216), CUSTOMER_LASTNAME VARCHAR(16777216) ); INSERT INTO "TEST"."PUBLIC"."STG_ORDERS" SELECT DISTINCT src:customer.address.address1::string as CUSTOMER_ADDRESS_ADDRESS1 src:customer.address.address2::string as CUSTOMER_ADDRESS_ADDRESS2 src:customer.address.city::string as CUSTOMER_ADDRESS_CITY, src:customer.address.country::string as CUSTOMER_ADDRESS_COUNTRY, src:customer.address.postCode::string as CUSTOMER_ADDRESS_POSTCODE, src:customer.address.state::string as CUSTOMER_ADDRESS_STATE, src:customer.email::string as CUSTOMER_EMAIL, src:customer.firstName::string as CUSTOMER_FIRSTNAME, src:customer.lastName::string as CUSTOMER_LASTNAME FROM "TEST"."PUBLIC"."raw_source" raw_source, LATERAL FLATTEN( input => raw_source.src:data, outer => true, path =>'items') as itemdata;
Step 3: Truncate the “landing zone” table
truncate table if exists "TEST"."PUBLIC"."raw_source";
This three-step process is simple to understand and easy to code and implement. And it’s operationally simpler to run a DISTINCT on a dataset than to scan a subset of data and process only the duplicated events. But there are significant drawbacks:
- DISTINCT is a very expensive operation; avoid it whenever possible. It scans the entire dataset and processes each duplicate. And running DISTINCT can also take a long time to process.
- It cannot correct wrong data. Because you’ve truncated the data from the “landing zone” table, if any data corruption happens downstream, you can’t re-process the data from its raw form without re-ingesting it from the source (again, expensive). This leads to data quality and integrity issues.
- It supports only batch processing. Streaming data is not compatible with this architecture because data latency is relatively high to run DISTINCT. That said, this approach is easy to implement.
Deduplicating Data in Event Processing Platforms
Exactly-once processing was introduced in Kafka 0.11. Prior to Kafka 0.11, it was only possible to achieve at-least-once or at-most-once processing.
- At-least-once processing avoids dropped data but results in duplicate data when failures or errors occur.
- At-most-once processing avoids duplicates but results in missing events because messages are not being recovered from failures.
Exactly-once semantics enables you to ensure that the messages are being written exactly once to the Kafka topic.
But it’s important to understand that exactly-once processing from Kafka does not solve the problem with duplicated data at the source. Exactly-once processing helps with failure scenarios. For example, if a producer, broker, or consumer fails, Kafka does not duplicate or drop any events. However, if the Kafka producer receives duplicate data from a source (such as a data warehouse table, logs, SaaS application, object storage, and so on), Kafka’s exactly-once processing still processes duplicated data, as it doesn’t know any better.
To close this gap you must do two things. First, you must configure the idempotent producer to ensure messages are published only once – even when a producer does not get an acknowledgement from the broker. For example:
new NewProducerConfig
{
BootstrapServers = "Server:9092",
ClientId = "YourId",
EnableIdempotence = true,
Acks = Acks.All
};
Keep in mind that Kafka only guarantees idempotent production within a single producer session.
Second, on the consumer side you must ensure the messages are read only once – no more, no less. You can use the following two approaches to solve the problem.
- Write an idempotent message handler. To do this, set
EnableAutoCommit = FALSE. When the application finishes processing, use synchronous API Commit to commit the offset. If you setEnableAutoCommit = TRUE, Kafka sends messages to the consumer and shifts the offset. But if the consumer fails, Kafka sends duplicate messages. - Keep track of processed messages and discard any duplicates. To do this, set
EnableAutoCommit = TRUE. Then commit the offset using Asynchronous APIStoreOffset. This means the consumer shifts the offset only after it receives an acknowledgement from the consumer that all messages have been processed.
How Upsolver SQLake Approaches Deduplicating Data
Upsolver SQLake provides an all-SQL experience for developing and continuously running pipelines that unify streaming and batch data while applying stateful transformations for output to data lake query engines, data warehouses, and other analytics systems. It comes with sample templates and data, plus a free 30 day trial for using your own data.
Data deduplication with SQLake is both simple and comprehensive. It solves the problem of high cost and performance issues that you encounter with the DISTINCT operation. And it deduplicates data coming from the source while also providing end-to-end exactly-once semantics.
Let’s take a look at a file with sample order data; assume the same file is being loaded to Amazon S3 every minute:
{
"items": [
{
"category": "rap",
"itemId": 2068,
"name": "lil mariko",
"quantity": 1,
"unitPrice": 397.63
},
{
"category": "jazz",
"itemId": 666,
"name": "john zorn",
"quantity": 2,
"unitPrice": 17.63
},
{
"category": "rap",
"itemId": 2068,
"name": "lil mariko",
"quantity": 1,
"unitPrice": 397.63
}
]
}
First, start loading from the S3 bucket continuously. This stages the raw data with the duplicates. Don’t worry – you’ll deduplicate the data in a subsequent step.
1. Create an S3 connection. Connections in SQLake are short SQL commands that hold the credentials used to access the resource’s data. You only need to create a connection in SQLake once. Once created, it stays active until deleted.
CREATE S3 CONNECTION upsolver_s3_samples AWS_ROLE = 'arn:aws:iam::949275490180:role/upsolver_samples_role' EXTERNAL_ID = 'SAMPLES' READ_ONLY = TRUE;
2. Create a staging table in the data lake. The staging table will hold the raw data copied from the source system, similar to the “landing zone” in the previous data warehouse example. There’s no need to define a schema in this step, because SQLake automatically detects, infers, and populates the schema and partition information as data is ingested.
CREATE TABLE default_glue_catalog.database_4b345d.duplicated_orders_raw_data() PARTITIONED BY $event_date;
3. Create an ingestion job to load the staging table. This job reads events from the source, converts them to Apache Parquet format, partitions the data, updates the metadata in the AWS Glue Data Catalog, and stores the files in S3.
CREATE SYNC JOB load_duplicated_orders_raw_data_from_s3
CONTENT_TYPE = JSON
AS COPY FROM S3 upsolver_s3_samples
BUCKET = 'upsolver-samples'
PREFIX = 'demos/blogs/duplication/'
INTO default_glue_catalog.database_4b345d.duplicated_orders_raw_data;
4. Execute a simple query against the staging table to validate data has been added.
SELECT orderid, orderdate, ordertype, nettotal FROM default_glue_catalog.database_4b345d.duplicated_orders_raw_data WHERE orderid = 'PoYa0UEIJ6' LIMIT 100;
The staging table will contain multiple items with the same ID:
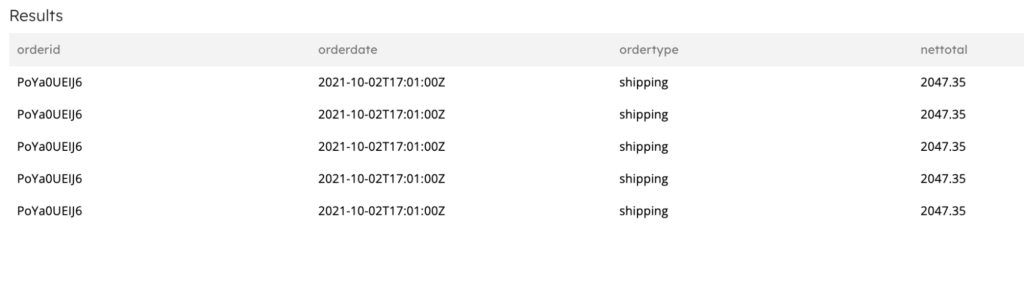
5. Create an intermediate target table and define orderid as the primary key. This table will hold the deduplicated data that you can use for future use cases where this dataset can be used.
CREATE TABLE default_glue_catalog.database_4b345d.orders_deduplicated_data( orderid string, orderdate date) PRIMARY KEY orderid PARTITIONED BY orderdate;
6. Create a transformation job to load the intermediate table. This job reads duplicated rows from the staging table and uses orderid as the primary key insert into the target intermediate table. By default, SQLake will use the orderid column to detect if a row already exists with the same value, in which case it will update it. If that orderid does not exist, it will insert the row into the target table.
CREATE SYNC JOB deduplicate_orders_by_upsert
START_FROM = BEGINNING
ADD_MISSING_COLUMNS = TRUE
RUN_INTERVAL = 1 MINUTE
AS INSERT INTO default_glue_catalog.database_4b345d.orders_deduplicated_data
SELECT
orderid,
orderdate,
ordertype,
nettotal
FROM default_glue_catalog.database_4b345d.duplicated_orders_raw_data
WHERE $event_time BETWEEN run_start_time() AND run_end_time();
Execute a query against the intermediate table and confirm the results do not include duplicate records.
SELECT orderid, orderdate, ordertype, nettotal FROM default_glue_catalog.database_4b345d.orders_deduplicated_data WHERE orderid = 'PoYa0UEIJ6' LIMIT 10;

SQLake continuously evaluates incoming records and removes duplicates based on the primary key. Not only is this process cost-effective – it also enforces data integrity and quality downstream. Businesses can run reports with confidence that the answers are based on the correct data.
Summary – Simplifying Data Deduplication
Managing duplicate data is not simple. There are many ways to introduce duplicate records into your dataset, but the mechanisms to eliminate them are not always straightforward and the easiest ones have drawbacks, such as using DISTINCT in the data warehouse (which can be very expensive) and TRUNCATE (which makes reprocessing more difficult).
SQLake makes it easy to ingest and stage the raw data as is, to maintain an append-only table that can be used for auditing and reprocessing. It also makes it easy to read from this append-only table and deduplicate records using a primary key, without the need to learn unique syntax. This approach is cost effective because it does not require the system to process large batches of data and doesn’t use compute-hungry DISTINCT operations.
Try Upsolver SQLake for Free
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. You can try SQLake for free; no credit card required. Continue the discussion and ask questions in our Slack Community.
Published in:
Blog
,
Building Data Pipelines
