
Explore our expert-made templates & start with the right one for you.
The Difference Between Star Schema and Snowflake Schema
-
 Upsolver Team
Upsolver Team
- Cloud Architecture
- September 23, 2020
Reduce Data Warehouse Costs by Up to 90% with SQLakeFind out how to build fast, performant BI reporting over an S3 Data Lake in our joint webinar with Looker. Learn key data preparation best practices that can have a major impact on query performance, and see how you can ensure data in dashboards built on AWS Athena is up-to-date – all while reducing querying costs. Watch it for free right here.
People and organizations constantly produce a lot of data. Generally, we want to store generated data to access it later. Data storing should be efficient in all aspects including speed, cost, reliability, security, etc. That’s why different approaches to data storing exist. One of the most popular approaches is a data warehouse.
Data warehouses are repositories of data from most recent operational processes. Data warehouses usually store structured and processed data that can be used for applications such as business intelligence or analytics.
There are several approaches and principles pertaining to what a data warehouse should look like, what architecture should be used, etc. One of the options the data warehouse developer should consider is the type of the schema. The star schema and the snowflake schema are among the most common. In this article, we will explore and compare them.
Star Schema in Data Warehouse
Regardless of what schema you use, it is always important to understand the basics of a fact table. This is the table containing core information about the business process. For instance sales revenue by product. This table can have references to many other tables. The type of relationships between tables in a data warehouse is the most important feature that defines the type of data warehouse schema.
For star schema, every external field in the fact table is represented by just one reference table. For example, consider the following fact table:
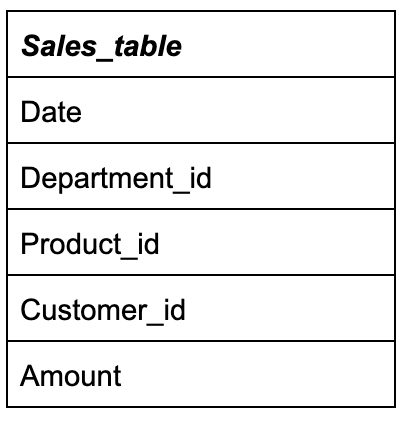
In this table, Department_id, Product_id, and Customer_id are the fields that contain references to an external table. Amount is just a numeric field. The structure of external tables can look like this:
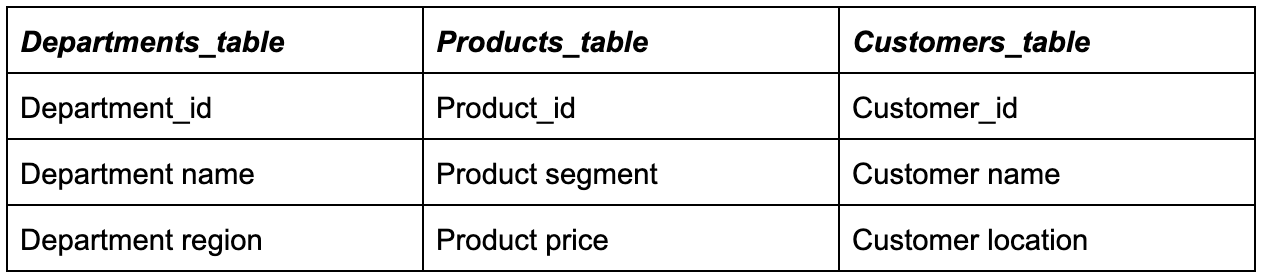
Reference tables have no relationships with each other: they are linked only by foreign keys (ids) with the fact table. The visualization of this schema resembles a star:
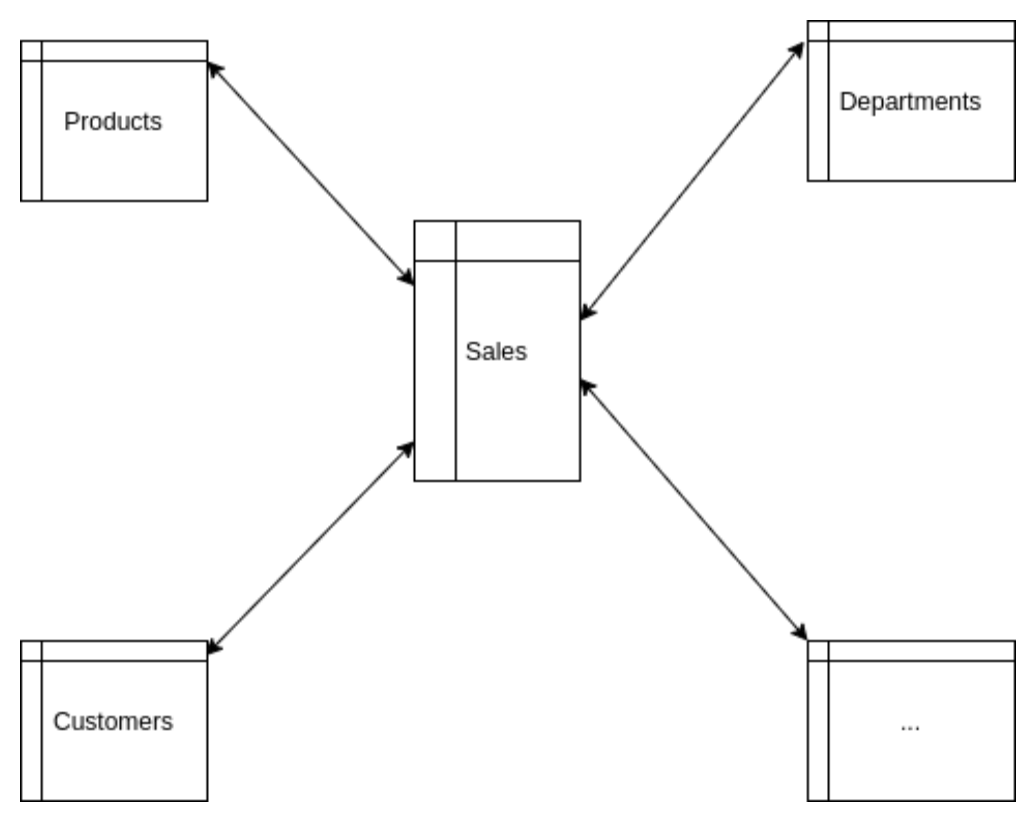
The important thing to keep in mind is that data is not fully normalized when using star schema. This means that tables such as Products, Departments, Customers, etc. don’t have their own lookup tables. So, information about products is stored solely in the Products table and nowhere else. It is obvious that a lot of data is duplicated (not normalized) with this schema.

Snowflake Schema in Data Warehouse
The snowflake schema is an extension of a star schema. The main difference is that in this architecture, each reference table can be linked to one or more reference tables as well. The aim is to normalize the data. Look at the Products table in the previous example. The Product segment field can be repeated many times for many products. But if we create one more table, Segments, we can just reference the Products table to the Segments table (using ids – foreign keys). The same can be done for the Customer location field in the Customers table or the Department region field in the Departments table.
Here is a visualization of the snowflake schema:
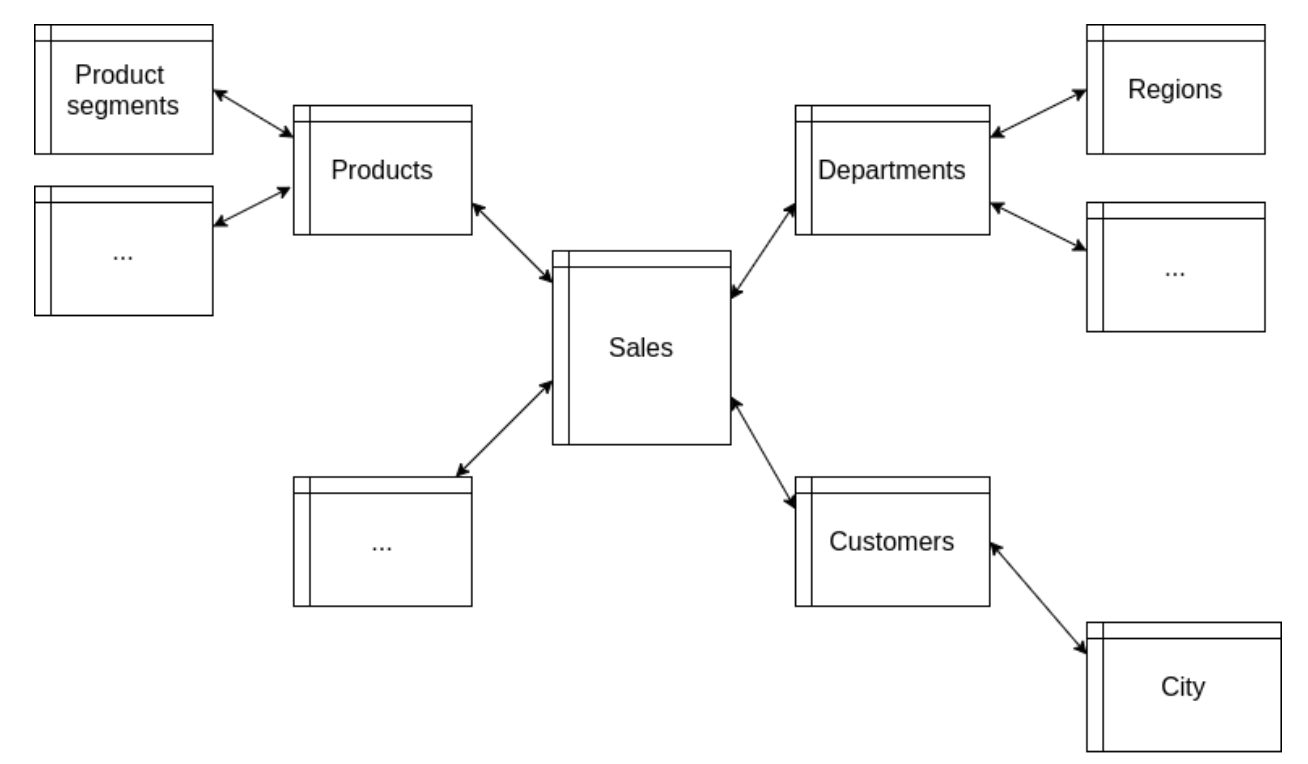
If there are a lot of different tables, this structure resembles a snowflake. It has the center (fact table), and many reference tables that make up the branching, similar to what snowflakes have.
Having more lookup tables allows perfect data normalization because less data is duplicated.
Difference Between Star and Snowflake Schemas
Let’s compare the most important features of star and snowflake data warehouse schemas.
- In a star schema, all information is placed in the fact table and the lookup tables that have a direct reference to the fact table.
In a snowflake schema, it is possible that the first-level lookup tables have their own lookup tables. So, the information is dispersed over the entire system.
This is the most important difference, and what all the following conclusions are based on.
2. Star schema results in high data redundancy and duplication. Snowflake schema ensures a very low level of data redundancy (because data is normalized).
3. Star schema is very simple, while the snowflake schema can be really complex.
4. In general, there are a lot more separate tables in the snowflake schema than in the star schema.
5. Snowflake schema uses less disk space than star schema.
Benefits, Disadvantages, and Use Cases of Each of the Schemas
Each schema has its own advantages, disadvantages, and recommended use cases. Let’s explore them a bit.
Benefits of the Star Schema
- It is extremely simple to understand and build.
- No need for complex joins when querying data.
- Accessing data is faster (because the engine doesn’t have to join various tables to generate results).
- Simpler to derive business insights.
- Works well with certain tools for analytics, in particular, with OLAP systems that can create OLAP cubes from data stored using star schema.
Disadvantages of the Star Schema
- Denormalized data can cause integrity issues. This means some data can turn out to be inconsistent at times.
- Maintenance may appear simple at the beginning, but the larger data warehouse you need to maintain, the harder it becomes (due to data redundancy).
- It requires a lot more disk space than snowflake schema to store the same amount of data.
- Many-to-many relationships are not supported.
- Limited possibilities for complex queries development.
Benefits of the Snowflake Schema
- Uses less disk space because data is normalized and there is minimal data redundancy.
- Offers protection from data integrity issues.
- Maintenance is simple due to a smaller risk of data integrity violations and low level of data redundancy.
- It is possible to use complex queries that don’t work with a star schema. This means more space for powerful analytics.
- Supports many-to-many relationships.
Disadvantages of the Snowflake Schema
- Harder to design compared to a star schema.
- Maintenance can be more complex due to a large number of different tables in the data warehouse.
- Queries can be very complex, including many levels of joins between many tables.
- Queries can be slower in some cases because many joins should be done to produce final output.
- More specific skills are needed for working with data stored using snowflake schema.
Choosing the Best Option
When is it better to use the star schema and when the snowflake schema? Let’s explore several use cases.
- The company has a lot of data about recent operations that have to be accessible by analysts. This is the use case where a snowflake schema may be perfect because you will save a lot of disk space compared to the star schema. Also, data can be needed for different users and different scenarios, so it is better not to limit the complexity of available queries.
- The snowflake schema is a good choice for situations where you intend to issue advanced analytics queries to the data warehouse.
- If the data stored in the data warehouse is not very large and/or it is not expected that business users will send complex queries, the star schema is what you need. It is simple, convenient for end-users, and allows for fast execution of low-complexity queries. Such data warehouses can be referred to as data marts and they are often created for separate departments of the organization, not for the business as a whole. The most important aspect of data marts is the convenience and speed of producing the output, and this is where the star schema is perfect.
- There are also a group of use cases where you are forced to use either star or snowflake schema because other instruments from your toolset support only one schema. Fortunately, the number of such use cases constantly decreases because more and more tools support both schemas.
However, many benefits or disadvantages can be smoothed out by modern technologies. For example, disk memory is becoming cheaper and cheaper, and powerful database engines provide a high speed of complex queries execution. So, each individual situation should be carefully explored.
Conclusion
In this article, we outlined the differences and similarities between two data warehouse schemas: star schema and snowflake schema. We highlighted the most important features of each of the options and explored their advantages and disadvantages. We also made recommendations regarding what schema is better in certain conditions. Remember, the main difference between these two schemas in terms of usage scenarios are disk space-saving and supported queries complexity.
Try SQLake for Free
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try SQLake for free for 30 days. No credit card required.
Published in:
Blog
,
Cloud Architecture