
Explore our expert-made templates & start with the right one for you.
Debezium for CDC: Benefits and Pitfalls
-
 Eran Levy
Eran Levy
- Change data capture
- November 21, 2023
Debezium has become a popular choice for change data capture (CDC) and is frequently used in production data pipelines. However, native Debezium is not without its limitations, which is why it would typically be a building block rather than a complete database replication solution. Below we explain some of the basics of Debezium, look into what it does and doesn’t do, and finally show how we implemented a managed version of Debezium at Upsolver to provide scalable CDC with minimal engineering overhead.
What is Debezium?
Debezium is an open source change data capture (CDC) platform. It allows you to capture row-level database changes in real time and output them as an Apache Kafka stream. From there, records can be processed by downstream applications or written into storage for database replication – forming the basis for scalable, fault-tolerant streaming data pipelines and systems
Why Companies Choose Debezium for CDC and Database Replication
Debezium’s flexibility, lightweight architecture, and low latency streaming make it a popular choice for CDC. It is also fairly easy to integrate into modern data stacks. Key benefits include:
- Support for a wide range of databases: Debezium has connectors for MongoDB, MySQL, PostgreSQL, SQL Server, Oracle, Db2, and Cassandra, with additional sources currently incubating.
- Open source: Debezium is open source under the Apache 2.0 license and backed by a strong community.
- Low latency: The architecture is lightweight and specifically designed for streaming data pipelines.
- Pluggable: Debezium works with popular infrastructure tools such as Kafka and Docker.
- Handling schema changes: Depending on the specific database connector, Debezium will typically provide some level of automation for handling schema changes. Note this is only on the source level and is not propagated downstream (as we explain below).
How Debezium Works for Database Replication
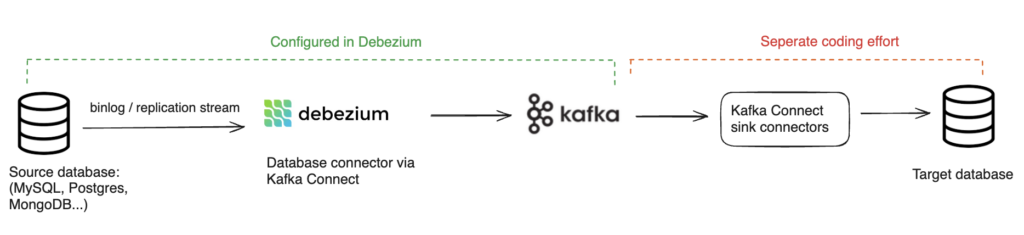
A typical Debezium-based pipeline would look like this:

There are nuances to how Debezium reads from each database, but the basic premise is similar. Debezium connects to source databases and captures row-level changes, typically in real time or near-real time. The database connector translates the change events into change data capture records with details like the table, changed columns, type of operation etc.
CDC records are then streamed into a Kafka broker. By default, this would be one table per topic, although this is customizable. Downstream applications can consume these Kafka topics to power reporting, analytics, data pipelines, and more. Debezium also offers mechanisms to manage schema and ensure at-least once (but not exactly-once) processing.
The most common way to run Debezium is using the Apache Kafka Connect runtime and framework. It’s also possible to run it as a server that streams changes directly into message brokers such as Amazon Kinesis or Google Pub/Sub; however, this requires running the embedded engine writing additional code to handle outputting, Including keeping track of offsets and what has been handled already.
Where it gets tricky
As with any software, there are trade-offs to using Debezium. Here are some of the potential complications you need to be aware of:
1. Ingesting the output stream into your target database (or data lake) is on you
Businesses usually want to replicate their operational databases in order to make them available for analytics – which means writing them into a database such as Snowflake or Redshift, or into a data lakehouse (S3 with Hive / Iceberg). However, Debezium’s role ends once the events are streaming to Kafka. From there, it’s up to developers and data engineers to ensure that the data arrives on the other side in the right format, on time, and that it accurately reflects the source data.
This is a non-trivial effort which involves managing and mapping tables in the target data store, validating data, managing schema per table, and handling incremental updates. In addition, ingesting any type of Kafka data at scale (e.g. to Snowflake) poses its own challenges. Open source Debezium doesn’t help with this, which means the full solution could incur significant additional overhead.
2. Ensuring continuous data availability and reliability
CDC pipelines are often meant to run continuously and ensure that fresh and accurate data is available for analytics at all times. While Debezium does offer some built-in capabilities for handling schema changes and late events, additional work will be required to ensure availability, reliability, and fault tolerance in scenarios such as downtime in the source database. This includes exactly-once semantics, handling breaking schema changes, ensuring availability, dealing with spikes in database traffic, and more.
You can find various guides in the Debezium community about how to deal with these types of production issues (e.g., here and here). As you can see, the process isn’t necessarily straightforward. You can therefore expect to need some kind of ongoing engineering support for this aspect of Debezium as well.
3. Kafka is a requirement
Debezium relies heavily on Kafka to deliver the change data captured from source databases. For companies that aren’t already using Kafka, this can be a major downside; managing a Kafka cluster requires continuous monitoring and tuning for factors like data retention policies, topic partitioning, and replication.
As data volume grows, Kafka capacity and throughput need to be managed actively to avoid degradation. Kubernetes and containers add further complexity when orchestrating Kafka in production. Operational tasks like upgrades, security patching, and failure recovery require significant engineering expertise.
4. Usual open-source challenges
Running open-source software like Debezium in production comes with inherent maintenance challenges. As with any software, bugs and security issues will be discovered over time that require patching.
With open-source tools, the burden falls on engineering teams to stay on top of new releases and manually upgrade production infrastructure. This includes testing to ensure stability and performance with each upgrade.
In cloud environments, container images and orchestration configurations need to be kept up-to-date across potentially large, distributed deployments. Falling behind on patches can result in degraded performance or serious security risks.
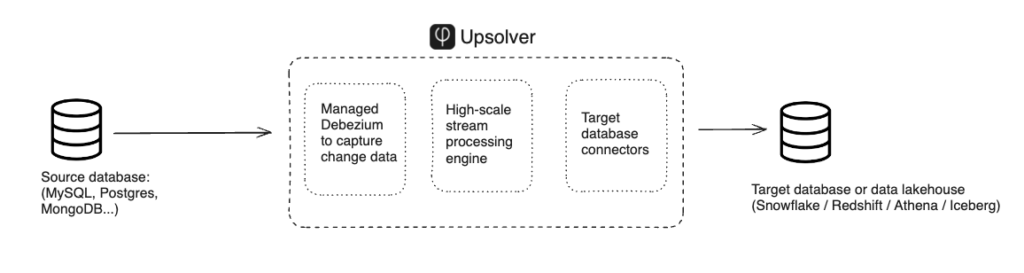
How Upsolver provides easy, scalable replication with Debezium under the hood
As part of Upsolver’s high-scale, developer-first data ingestion platform, we provide a fully-managed CDC tool that lets you duplicate petabytes of production data into your analytics databases. We’ve actually implemented Debezium under the hood (in a way that’s invisible to users), but introduced a bunch of improvements to offer complete source-to-target database replication with the absolute bare minimum of configuration overhead.
Let’s start with the end result – how you would build a CDC pipeline from SQL Server to Snowflake in Upsolver:
You can see that the process is simple and straightforward, doesn’t require the user to manage Kafka, and the entire pipeline is managed in Upsolver. Now let’s look at some of the automations and improvements that Upsolver introduces over open-source Debezium in order to enable this workflow.
Automating the manual parts
These are the things that Debezium does, but might require significant effort when using the open-source platform. Upsolver simplifies or automates them completely:
Taking Kafka out of the equation: As we’ve mentioned above, deploying open source Debezium means managing Kafka on both sides of the pipeline. Upsolver runs Debezium on its own engine based on SQLake tables and there is no message broker to manager. You simply point at the source and target and you’re good to go (using code, low-code, or no-code).
Snapshotting: Debezium uses snapshots in order to determine which tables to replicate and identify when new ones have been added. While support for incremental snapshots has been available for a while, it requires additional configuration and implementing various other mechanisms in order to signal when a snapshot is required. Upsolver automates the process and implements parallel incremental snapshotting without the need for manual configuration.
Handling errors in CDC streams: Debezium reads change events from the database’s binlog or transaction log, which contains a sequential history of all data changes that occurred in the database. Debezium is designed to continuously synchronize with the binlog and convert the change events into a real-time stream of changes. However, issues like database downtime or gaps in the binlog often require manual intervention to resolve. For example, if the binlog falls out of sync, a full re-snapshot may be needed to reset the replication process.
Upsolver automates recovery from many failure scenarios such as this one. If the binlog becomes outdated, Upsolver will automatically handle re-syncing without the need for human intervention. This simplifies operations and minimizes downtime when issues inevitably occur in production environments.
Managing data ingestion into the target data store
As we’ve mentioned, these are aspects that Debezium doesn’t handle at all, and relate to ingesting the CDC stream into your target analytics system (e.g., Snowflake):
Managing tables: In order to write a Debezium stream into a database, we need to ensure the target has a table defined for each source table that is being replicated. The table schemas also need to be mapped properly from source to target. For example, when a source table name changes, corresponding updates might need to be made on the target database side.
Upsolver automates schema and table management end-to-end. It will automatically create target tables mapped to the source, keep the schemas in sync during incremental changes, and handle various cases such as renamed tables.
Schema management per table: With Debezium, the initial source database schema must be manually created in the target database. After this, further effort is required to propagate incremental schema changes made to source tables. For example, adding or removing columns in the source would require corresponding ALTER TABLE commands run manually on the target.
Upsolver automates schema change management across the source-to-target pipeline and ensures that the data and schema are reflected on each side. Upsolver also handles potential breaking changes like column data type changes through automated schema evolution to reduce any potential downtime or degradation in data quality.
Per-minute ingestion, at scale: There are many other challenges when moving very large volumes of data – such as managing costs, maintaining data quality, ensuring data availability and freshness, and managing streaming transformations. At higher scales (terabytes to petabytes) these could overshadow the initial challenge of extracting the data from the source.
Upsolver’s cloud platform is used by leading companies to move petabytes of data into AWS data stores, which means the business gets a complete solution for moving and operationalizing data, rather than a piecemeal component that requires further engineering work.
Summary: Native Debezium vs Upsolver
| Open Source Debezium | Upsolver’s managed Debezium and data ingestion | |
| Connect to source databases | ✅ | ✅ |
| Handling schema changes in source database | Partial | Automated |
| Incremental snapshotting | Separate effort | Automated |
| Error handling | Separate effort | Automated |
| Schema and table management in target database | ❌ | ✅ |
| Data quality in target database | ❌ | ✅ |
| High scale ingestion and transformation capabilities | ❌ | ✅ |
Try Upsolver for Free
Want to try Upsolver for yourself and see how it compares to other CDC tools? It’s easy and free – and you’ve got two options:
- Recommended: Schedule a walkthrough call with a solution architect. We’ll help set up Upsolver in your environment and teach you some valuable best practices to help you get the most out of your trail.
- You can create a free account here and start self-evaluating immediately.
Published in:
Blog
,
Change data capture