
Explore our expert-made templates & start with the right one for you.
1 Engineer + 3 Weeks = Data Lake + Data-Driven Apps
-
 Roy Hasson
Roy Hasson
- Use Cases
- August 10, 2022
Recently Upsolver Head of Product Roy Hasson talked with Proofpoint’s VP of R & D Alon Horowitz about Alon’s first foray into big data (with Meta Networks, a company Alon co-founded that Proofpoint has since acquired). Proofpoint is a cloud provider of cybersecurity solutions intended to help companies stop targeted threats, safeguard their data, and make their users more resilient against cyber attacks across multiple channels – email, the cloud, social media, and the web. Alon deployed Upsolver on an AWS data lake as his foundation for building applications and dashboards that deliver near-real-time data and insight to its customers.
This conversation has been edited for brevity and clarity.
Roy Hasson: So, Alon, tell us a bit about how you use data.
Alon Horowitz: We have a global network of POPs, or points of presence, which create a mesh network. It allows our customers to connect resources from everywhere. It doesn’t really matter whether you are in the office or abroad. Basically you get sort of a flat network, where you have access to all your Internet resources from anywhere in the world.
When you create a distributed network, you usually want to connect to the closest place to you. Let’s say I’m connecting to the POP in Israel, but information is in Frankfurt. So I’m going through the Proofpoint POP closest to Israel. We route the traffic through the closest POP to Frankfurt. We check all the policies for compliance and then we pass information to the station. So POP is like, when you have a CDN you go to the closest location to you. We have like a hundred POPs. A very big number.
We collect a lot of data, a lot of metrics. Basically we see how many users are connected to each POP, and from which countries. We see the active users across months. We have a lot of traffic, a lot of information about throughput, about users, top users, meaning the user that creates most traffic in the organization. And because we get a lot of events, we get a lot of information about all DNS queries being done on our platform – sessions and things like that.
Roy: Tell us about what got you started on this journey.
Alon: We already had all the DNS queries. We had all the sessions, every PCP connection, all the dumps. And we had many types of information, and we knew it was valuable for our customers. We knew we wanted to do something with it. We just didn’t know what exactly. And this got me thinking.
I wanted a solution that won’t limit me in the amount of data that I have. I just wanted to keep everything in an efficient way and to store everything.
Roy: How big was your team? What was their skillset?
Alon: Well, we were only five people at the time – this was about 5 ½ years ago – and we didn’t have many developers to spend on a big data solution at the time; we were mostly focused on networking and security and things like that.
Roy: What solutions were you considering?
Alon: So, actually the alternative for me was to actually start writing everything with Spark, because usually everything we’d done so far was writing ourselves or using open source solutions. And we wanted to get into Spark. We wanted a data lake and we needed to dig into what was the right way, you know, to write everything, to keep everything and to evolve all the things that we might run into in the future.
I think Spark is great. But it’s a learning curve. You can’t just start and, you know, get in data without thinking about it. It’s an expertise.
Roy: And you also have to know how to troubleshoot it. If you don’t really understand the ins and outs of Spark, it becomes hard to scale and to make sure your pipelines stay up and running. And I don’t think anybody wants to wake up at two or three in the morning because some pipeline blew up.
Alon: Definitely. And it’s pretty hard to size it. I wanted one developer to run all of this operation on top of Spark. But I didn’t think one developer could do it. I think it would require me to build that small team. And when you have a small startup you don’t really want to focus hiring people to work on something that’s not your main use case.
Roy: Especially when you don’t have data engineers who are well-versed in it, or who didn’t understand how to do it.
Alon: Also we love actually “buying time.” If we can pay for someone to take care of things, we’d usually do that.
Roy: So what did you look at, besides Spark?
I looked at two solutions. One of them was more like a, like a managed service that actually keeps the information for us. It’s like a platform or top of a database or data warehouse solution where you keep everything on their solution. But I didn’t want anything like that. I wanted to control the data lake.
Then I found Upsolver doing a search for “data lake.” I spoke with (Upsolver Co-founder and CEO) Ori Rafael, and Ori offered me a solution that allowed me to store everything in a data lake, which they would process for me. And they will keep everything in a very efficient format, you know, in Parquet format, with Snappy compression, everything.
He said I wouldn’t need to spend too much time or effort or need too much big data knowledge to run it. So the only concern at the time was, what if I wanted to leave it after I tried it? But it wasn’t really an issue for me because the format is a standard format, Parquet. With Upsolver, basically I have everything in a standard format and I can, you know, leave at any point in time. So, I said, why not? I’ll put a single developer on it and see how everything goes.
Roy: Was that a data engineer you put on it?
Alon: No, no, he didn’t actually have any prior knowledge in big data per se. He actually came from storage. He was just a very talented engineer.
Roy: So what happened when you got started?
Alon: He started playing with the system, and with some help from Upsolver, after three weeks, we created a simple data lake on top of S3, in a Parquet format, and we just started basically offering a simple report to our users. Meaning we ran queries and then we aggregated information, gave them an email saying, hey, in the last month you had this and that users, with this and that traffic, and so on and so forth. This was the basic use case that we got after three weeks.
Roy: So was the data that Upsolver wrote into your data lake on S3 pretty much ready to go? You didn’t have to do any extra work to make it queryable, right?
Alon: No, no, no. It was complete.
Basically, it’s a lot of types of aggregation on top of data that we collect from the server, which is pretty cool. We stream from all our POPs, a lot of information, which is pretty raw. And we stream a lot of information from our management plane and we mix it all together and enrich it. And then we get to more valuable information, which we can then deliver to our customers in an efficient way. That’s the high level of what we did at the time.
Roy: Got it, got it. Now, do you have Kinesis in different regions or is it a single region?
Alon: No. What we actually ended up doing is basically deployed Kinesis in key locations. We didn’t place Kinesis in each POP because it’s too much. We created, I think, two per continent or something like that. Aggregated, meaning you have multiple Kinesis instances in multiple locations, which run into another Kinesis stream and then run into Upsolver. So Upsolver just gets a few Kinesis streams. But on the way data goes through multiple streams.
Roy: And the data coming through Kinesis, this is raw data. There’s no aggregated events in there.
Alon: No. nothing. We just keep it in a flat format, meaning it’s JSON, without any special information beside IP addresses, IDs, you know. You can imagine when you handle networking, it’s pretty low level. We don’t know the user ID at that time.
Roy: Got it. And so you take all these raw events, you aggregate them inside Upsolver. Did you have to add more developers?
Alon: No. Most of the work was done by the one developer. In fact, it’s the same developer to this day that still leads mostly by himself, all this big data effort. I think he had one other developer at one point in time to help him, but most of it is a one-person job.
Roy: A common question that we get from a lot of our customers is that they have a lot of raw data and they want to be a data-driven company and they want to deliver some of that data value to their users, but they struggle to get that data to their dashboards, to their applications. Can you talk a little bit about some of the challenges you faced in doing this?
Alon: There’s a management layer on the top with a lot of microservices in a VPC in AWS. Underneath, you see points of presence in many locations. We have information coming from POPs, from all around the world, and we have information coming actually from the microservices themselves – attempts for authentication, API posts, things like that. And all the personal information is actually kept in the management plane.
The information coming from the POP is pretty low level. Meaning you see IPs, but you don’t really see information about the person. So one of the challenges that we ran into is how you take all this information and enrich it in a way that makes it more valuable for a customer. I didn’t want to write things like “this IP address got access to this server”. I want to write, “Roy got access to Jenkins and he didn’t get access to Travis because of a select policy,” or something like that. This is the language that I wanted to deliver to the customers.
And this was a challenge because it’s coming from a lot of POPs, from a lot of locations. You can imagine that when a user browses the Web, they generate a lot of TCP connections and a lot of traffic, and it generates a lot of events. It’s even hard to size it at the time. So the challenge was both scale and the different streams with different types of schema, which we want to mix together,
Roy: You kind of alluded to the volume But I think it’s worth mentioning the type of data. Is it structured? Is it nested?
Alon: So we try to keep everything in the same structure, meaning most of it, we try to make it as flat as possible, in JSON format. But, you know, some events have more fields than others. For example, a connect event is completely different from the fields and information in an authentication event or a security event. So a lot of types of events.
We didn’t want to actually commit to the structure because we kept adding fields as we moved along. So, yeah, this was one of the issues that we ran into. And what we did was, we added a Kinesis stream. Actually multiple Kinesis streams, but for the sake of this discussion, let’s say one Kinesis stream. And we started sending traffic from all our POPs, to the Kinesis stream. Imagine all the POPs sending information there. And not just all the POPs; also from our microservices. And then we basically used Upsolver to take all those frames and basically enrich them together and make something more valuable out of them.
Roy: Did you run into any issues where you felt stuck, or had to put something on hold? Like, a use case you couldn’t support because the technology just wasn’t there?
Alon: Upsolver offers a lot of aggregation functions. It’s pretty hard to remember all of them. Usually I ended up asking whether you support this or that. And usually the answer is yes. Or we can support it in no time, which is nice. And we do a lot of things, from parsing IP addresses to grouping by a lot of different keys, compound keys and things like that. Everything.
Roy: Can you give us an example?
Alon: Let’s take a look at this event, for example.
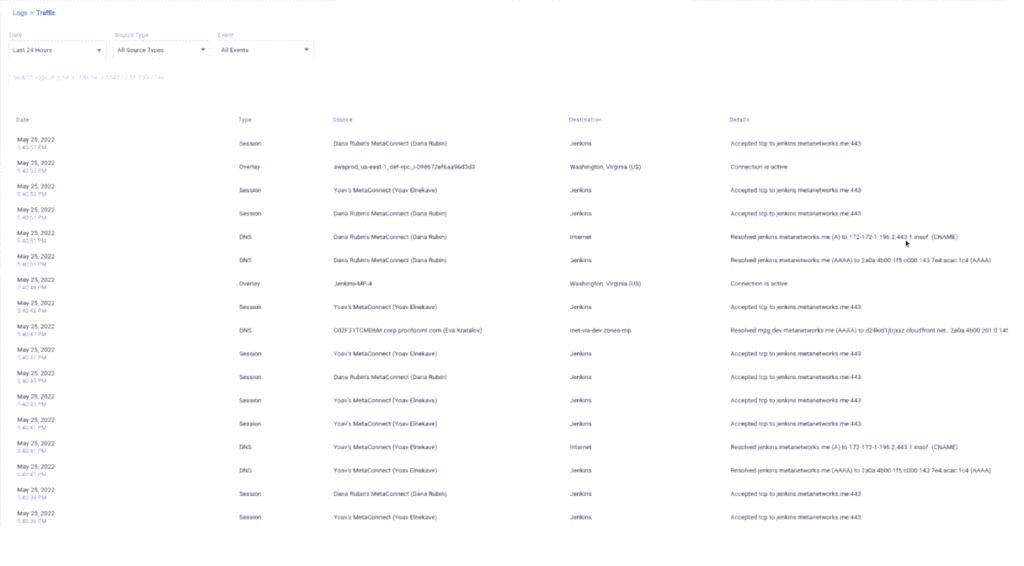
You can already see the source, like Dana, Rubin, and Jenkins. All those names are the results of the enrichment coming from Upsolver. You actually see names, you see unions, you see names of services. We kept the IP in the details because it’s important. If you want to dig in, you can actually click on the lines and you see more information, but it’s still something you can read. And that’s the beauty of it. And this is what we actually kept in Parquet format. And it’s analytics-ready – Athena works out of the box once it reaches S3. So once we started writing these events coming from our POPs and our microservices into S3 with Upsolver, we were just able to quickly start running queries against it.
Roy: Were these queries for your team to kind of understand the data exactly, or for your business users, building dashboards on top of that – how did you use that data?
Alon: For investigating the system. We wanted to see how many users are using it. Maybe, you know, provide something for the marketing team.
Roy: OK. So what happened next? When did you realize you could start doing more with what you’d built?
Alon: Pretty soon we saw that this is super valuable for our customers and wanted to give our customers an ability to look at all this information, all those logs in a fast way. And once you talk about fast, Athena is not the right solution to do it, because with Athena, every query takes a lot of time and also costs money. So we wanted a way to allow our customers to run search queries for their information, at least for the last, let’s say, four , six week. So we added Elasticsearch to our management plane in a T-like architecture. Basically we had Upsolver write the same information both to Elasticsearch and to S3. In that way we kept everything in log retention, meaning indefinitely, but in Elasticsearch we only kept the last, let’s say, 4 weeks. And this allowed us basically to provide a search API. And you can search events in seconds. And this is super valuable for our customers. They get everything in a nice table, a searchable table.
Roy: We see this kind of thing with customers. And it’s simply two pipelines. They take the same source. They write the raw data into S3, ready to query with Athena, and then they take the same data and write into another output — in this case Elasticsearch. So you can integrate with the application and get full search and stuff like that.
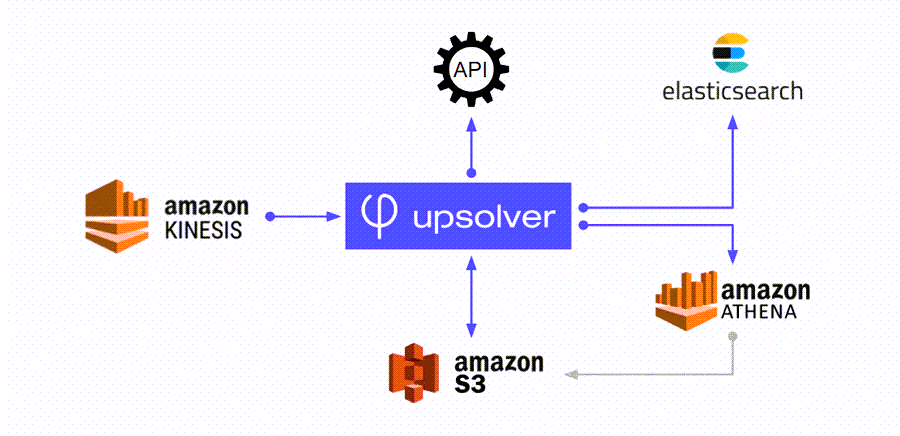
Alon: Athena is great, but if you want something quick, more real time, you have to have Elasticsearch or something like that. We are paying for it by the fact that we have the same information twice. But it’s worth it to keep the information twice, at least in the short term, in order to get a good experience for our customers.
Roy: Yeah. That makes sense.
Alon: Okay. And once we actually added all the information, our customers started saying, “Hey, we have all this information, maybe provide us a platform for creating alerts. Well, once you have Elasticsearch, it’s a breeze. We created a rule mechanism that allows the customer to create alerts, then look for events like a security breach event or a policy violation event. We already had user information, like “Dana violated the policy.” And we just sent alerts to the customer, like text notification, email notifications, all on top of this information.
Roy: How else are you leveraging Upsolver?
Alon: So we wanted to provide metrics to the business because we had all the information. One of the cool things in Upsolver is you have a materialized view, which is where you can basically take all the logs, accumulate them into a materialized view, and then you can query them in real time.
So rather than having an API gateway or another database that holds that information, we actually get a materialized view of the data in real time as new data arrives, accessible from our application via API. So that’s really powerful. The same stream of data can get represented in many different ways. The materialized view summarizes the amount of data from each user, and basically sorts it by the top users. The users with the most traffic.
Roy: That’s really powerful – the same stream of data gets represented in three different ways, in your example – S3 tables, Elasticsearch for customers and via API for reporting
Alon: Exactly. And it’s quite accurate – one microsite goes directly to the material view, another microsite goes directly to Elasticsearch. So basically the combination of the materialized view and the Elasticsearch gives us pretty good coverage. Those are the main cases that we use.
Roy: I’d like to understand a little bit more about the use of materialized views. What kind of transformations do you do inside of Upsolver, and how do you interact with the materialized views from your microservices?
Alon: Okay. Let’s say for example we have multiple user connects for multiple POPs. And what you really want is the aggregation of an organization, the amount of throughput that an organization had in a period of time. So we take TCP events, each TCP event basically as its payload and the amount of traffic that went through this session. So imagine a lot of events coming from multiple locations. Everything gets run into Kinesis – by the way, this information only contains IDs, things that are pretty raw – then into Upsolver, and then we group by the organization ID. Or the tenant ID. And then we enrich the information of the tenant with the information that comes from the management layer, which is a different stream – for example, the organization name, things like that. And then you get a materialized view where each key is an organization with the throughput over the last month – usually as an array of buckets. Each bucket is an interval in time, which is averaged.
Roy: Were there any capabilities that Upsolver gave you that you hadn’t planned for? Things you discovered you could accomplish once the platform was in place?
Alon: I think the one that I was mostly surprised by was around Elasticsearch and GDPR. Because we didn’t think about GDPR at the time, which is not a good thing to do by the way, next time, I’m going to think about GDPR as I start. But after you have an accumulation of data, it becomes a real issue.
One of the challenges to GDPR is, we wanted a data lake. And we keep everything enriched with sensitive information in the data lake. Which basically creates a problem. How do you delete a customer organization?
Roy: It’s not that easy to delete information across a data lake.
Alon: Right. You need to go through a lot of data. So we thought a lot about it. And what we came up with was, because we had this T-like architecture, we decided to basically keep the information with the sensitive information in Elasticsearch. But in S3 we anonymized the information. Meaning you only see IDs and things like that in S3. And as long as the customer is in our system we still have the mapping in our management plane.
So let’s say I want to create a report. I only have anonymized information, but I can still cross-ref with the information in the database. But once the customer deletes his information, I don’t really need to delete the data. I just have to lose the keys, right? And so instead of deleting the data from the data lake I just lose its meaning. And this solved it for us. And basically it was Upsolver that allowed us to make sure that one stream is anonymized while the other is not.
Roy: But how did you solve for GDPR retroactively? I mean, you had to have data that pre-dated Upsolver that you also had to anonymize, yes?
Alon: You raise an interesting point. Because when we moved to GDPR, we already had information that was six years old, let’s say, four years old at the time. One of the cool things is the ability to back up and/or replay all of the information again, and rewrite it in the new schema. So we created a cluster for the legacy data. It worked a few days a week, I don’t even know the time. But after that we created a new data lake with all the information in the new schema. And we didn’t lose information that we started with six years ago.
Roy: You know, the data replay part tends to come up often in conversations with customers. We’re like, yeah, we can drop it in. We can start looking at the raw data and the new data coming in. And it’s great, but what do we do about the old data? Like how do we replay it? How do we get it back into the platform?
And it’s also in a streaming world, right? Like when we talk about batch data, that’s one thing. You can just replay the batch data. But what about when your data is sitting inside of Kinesis? And that’s where the data is, and you have to replay some data for whatever reason. It’s the same kind of mechanism.
Alon: It actually already made my life a little easier, when we got acquired by Proofpoint. Because Upsolver doesn’t really store the data, it just processes it. And this makes things a little easier, security wise. And it’s pretty hard to explain to management why all your sensitive data is kept in a third party system. The fact that everything is only in our S3 makes it easier.
Roy: So what’s the next thing for this data architecture or this data platform for you? What is kind of the next thing on your roadmap?
Alon: Actually, it’s not a new architecture, but basically we’re using the same solution for another use case. We are creating a new product, like a Web Security Gateway, where we get a lot of information. But this time in a layered service solution. Meaning we get a lot of traffic – a lot of information about where you access URLs, things like that, you know, return codes. Everything is layered service. And you already have POPs. It’s not like a full networking mesh. It’s more like, you get to the closest POP and it takes care of all the security stuff. But the big data solution part is basically a copy paste from this one. Basically we did the same thing again, and it worked beautifully for a completely different solution.
Roy: So you’re replicating the same type of model.
Alon: Yeah. It’s more use cases and we keep adding them up.
Roy: So I just wanted to take a couple seconds here and just kind of wrap it up. Here’s where I get the plug in for Upsolver.
It’s extremely valuable to develop your pipelines in SQL and then leave all the automation, all the orchestration, all the management to Upsolver. Ease of use. You can actually build an architecture just like Alon showed us without data engineers. That’s the biggest takeaway.
And it’s important also to be vendor agnostic. You hear a lot in the market today, um, you know, different file formats, different table formats, lake houses, et cetera, et cetera. Those are great. And some of them are open source. But at the end of the day your data needs to be in an open format so that if tomorrow you want to go and you want to do something else with that, that tool allows you to do. You should not be blocked. You should be able to just go do it. If you want to migrate from one cloud to another, or do whatever you want, that data is yours.
And finally, performance. When our customers are comparing Upsolver to tools like Spark, not just the ease of use of building pipelines, but also the performance, especially when we’re talking about stateful operations like aggregations and joins across streams, at scale. That’s really, really hard to do. And if you look at Spark and the way they handle it, it works fine for smaller workloads, but for the larger ones, it starts to fall apart and it becomes a management overhead issue for you.
So again: Ease of use of developing pipelines, and the simplicity and automation of the operation side of it is really what Upsolver gives you.
Thank you very much, Alon. This has been a really awesome conversation.
Alon: You’re welcome!
Upsolver Offers SQL Data Pipelines to Unlock the Value of your Cloud Data Lake
Upsolver’s streaming data platform for cloud data lakes uses a declarative approach based on SQL transformations to eliminate the complexity of writing code and orchestrating pipelines on raw object storage. You get simplicity combined with data lake power and affordability.
Using only declarative SQL commands you can build pipelines without knowledge of programming languages such as Scala or Python. Upsolver automates the “ugly plumbing” of orchestration (DAGs), table management and optimization, and state management, saving data engineers substantial amounts of data engineering hours and heartache. This reduces from months to weeks – or even days – the time it takes to build pipelines and place them into production – even if you’re executing joins on streams being ingested at millions of events per second. You don’t have to become an expert on distributed processing. You don’t need a separate orchestration tool; you don’t need to deal with orchestration at all. And you don’t need to deploy a NoSQL database for state management at scale.
- To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo.
- Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
If you have any questions, or wish to discuss this integration or explore other use cases, start the conversation in our Upsolver Community Slack channel.
